
联系我们
手机: 13813816000
电话: +86 025-51865620
传真: +86 025-51865600
地址: 南京市建邺区嘉陵江东街50号康缘智汇港1号楼2401室
E-mail:bojia_tech@vip.163.com

高管概述
人工智能是信息时代的尖端科技。 计算的飞跃建立在人类告知计算机如何表现的基础上, 计算建立在计算机学习如何表现能够对每个行业有意义的基础上。 虽然目前可能被视作在下一个 AI 冬天(图 8)之前的最新承诺和失望循环,这些投资和新技术至少将给我们带来机器学习产品的实实在在的经济利益。
与此同时,人工智能、机器人和自动驾驶已成为流行文化的前沿,甚至是政治表述。但是,我们去年的研究让我们相信这不是一个失败的开端,而是一个拐点。我们将在这个报告里看到,宏观(更多更快的计算和更多数据的爆炸式增长)和更加微观方面(在深度学习方面的有益进展,智能硬件和开源方面的增长)的拐点的原因。
关于人工智能拐点的更多令人兴奋的方面之一是真实应用案例的增加。 例如深度学习促进计算机视觉的发发展, 这些技术做为自然处理语言引人注目地提升了苹果 Siri、 亚马逊 Alexa和谷歌图片识别的质量,人工智能不是为了技术而技术。大数据和强力技术相结合,创造价值,获得竞争优势。
例如,在医疗领域,图像识别技术可以促进癌症诊断的准确性。在农业领域,农民和制种者可以利用深度学习促进产量增长。在制药行业,深度学习被用于发现新药。 在能源行业,勘探效率和装备可靠性提升。在金融服务行业,同以前可能的相比,成本降低,新数据应用于更快速的分析,返回结果。人工智能在应用案例发掘的非常早的阶段使用,同时做为基于云服务共享的必要的科技,我们相信一波革新将到来,为每个行业创造新的冬天和失业者。人工智能广泛的适用性也让我们认识到它是全球经济的针移技术、 提升效率和结束美国经济增长停滞的驱动。利用 GS 首席经济学家 Jan Hatzius 的研究,我们设计了当前的深度资本不景气指数和它对美国生产力的相关影响。我们相信人工智能技术驱动生产力提升的可能,就像 1990 年一样,驱动更多的资本合作和人力效率提升项目,促进增长,促进盈利,扩大股票价值。
我们发现人工智能实实地影响着每个公司、行业和经济因素,对投资者有四个方面值得注意。
生产力。人工智能和机器学习有引发生产力增长的潜力,有益于经济增长,公司盈利,资本回收和资产估值。根据 GS 首席经济学家 Jan Hatzius“原则上,人工智能看起来的确比上一波革新在统计学上有表现更好的潜力,人工智能降低成本和人力需求, 更高的产品附加值类型。”例如,同 iPhone 应用的多样性和可靠性相比,统计学家可能更好的建立并获得这些商业部门的费用节减革新。 广义的人工智能对商业部门的费用结构有广泛的基础性影响, 我由衷相信人工智能将被统计学家采纳,并在整体生产力数字中有所展现。”
优质科技。 人工智能和机器学习的速度价值有扭转更便宜的数据中心和网络硬件的趋势的潜力。我们相信这将驱动硬件、软件和服务领域市场费用的大量变化。例如,1 条运行在标准数据中心上的 AWS 工作量, 同在人工智能优化后的 GPU 上运行所需的 0.9 美元相比, 每小时实际计算成本只要 0.0065 美元。
竞争优势。 我们看到人工智能和机器学习在改造各行业竞争订单方面的潜力。 那些失败于投资和平衡这些科技风险的管理团队被竞争者超越,这些竞争者受益于他们创建的战略情报、获得的生产力和资本效率。在 41 页插图中,我们论证了这些竞争优势是如何应用于医疗、能源、零售、金融和农业。
新公司创建。近 10 年来(图 69~75)在人工智能和机器学习领域,我们已经识别出有超过150 家私营公司.我们相信人工智能的大部分价值将由拥有资源、数据、投资能力的大公司获得。我们希望风险投资家、企业家和技术专家继续驱动新公司的创建,反过来,驱动实质性的创新和价值创造,至少是,M&A,我们不能无视谷歌或脸书的人工智能出现的可能。
接下来的内容中,我们深入了解人工智能,它的历史,由机器学习、围绕这些技术应用的一路领先的行业和公司所构建的应用生态体系。
人工智能是什么?
人工智能是制造智能机器、 可学习计算程序和需要人类智慧解决问题的科学和工程。 经典地,这些包括自然语言处理和翻译,视觉感知,模式识别,决策制定等,但应用的数量和复杂性在快速增长。
在这份报告中,我们将大部分分析聚焦在机器学习、人工智能的一个分支、深度学习、机器学习的一个分支。我们总结了二个关键点:
1. 简化地,机器学习是从案例和经验(例如数据配置)中习得的算法,而不是依赖于硬件代码和事先定义的规则。换句话说,不是一个开发者来告诉程序如何区分苹果和橘子,而是算法本身通过喂养数据(训练) ,自己学会如何区分苹果和橘子。
2. 深度学习的主要发展是现有人工智能拐点的驱动力量之一。 深度学习是机器学习的分集。大多数传统机器学习方法和特点(例如,可能预测的输入和属性)由人来设计。特征工程是一个瓶颈, 需要有意义的特定技术。 在无人管理的深度学习中, 重要特征不是由人类来定义,而是由算法学习和创建。
什么是神经网络?
神经网络在 AI /机器学习的中充当一种模拟人类大脑的计算机体系结构,在其上可以构建AI /机器学习程序。它由聚合的连接节点组成,如人类大脑中的神经元般可以解决更复杂的问题并学习。
什么是深度学习?深度学习是一种需要训练大型神经网络的“深层”层次结构,且每层可以解决问题不同方面的机器学习,从而使系统能解决更复杂问题的。 使用上面说到的火车的例子,深层学习系统包含了识别火车的不同特征的各个层。例如,底层将标识是否具有窗户。如果答案是肯定的,下一层将寻找是否有轮子,接下来将会识别是否是长方形的车等等。直到这些层共同地将图片识别为火车或彻底否定。随着技术发展,可以支持大型神经网络的训练,深度学习作为增强机器学习能力的方法已经越来越普遍。
什么是监督学习?无监督学习?监督和非监督学习是机器学习的两种类型。在监督学习中,系统给出一系列“正确答案”的例子。基于这些例子,系统将从正确的答案中学习什么是对的,从而进行正确预测的输出。监督学习的现实应用包括垃圾邮件的检测(例如,系统可能有一组标记为“垃圾邮件”并且学习正确识别垃圾邮件的电子邮件)和手写识别。
在无监督学习中,系统没有给出正确的答案,而是提供需要自己去发现特征的未标记示例。一个示例将基于大量客户数据中发现的, 包括可以将客户分组的某些特征 (例如, 购买频率)。
什么是一些类型的机器学习?
分类。将电子邮件归类为垃圾邮件,识别欺诈,面部识别,语音识别等。 聚类。对比图像,文本或语音找到相似的项目; 识别异常行为的集群。 预测。 基于网络活动和其他元数据预测客户或员工流失的可能性; 基于可穿戴数据预测健康问题。
什么是通用,强大或真实的人工智能? 通用,强大或真实人工智能是,机器智能算法完全复制人类智慧, 包括人类的独立学习和决策能力。 虽然像全脑模拟这样的技术被用于实现通用 AI 的目标,但是其所需的计算能力数量,仍然远远超出了当前的技术,使得通用的人工智能基本只存在于理论层面。
为什么现在人工智能加速发展?
请记住, 我们并不关注于重复独立人类智能且在流行文化中常见的真实、 强壮或普遍的人工智能。必然存在潜在突破点,例如谷歌深度思维 AlphaGo 系统,不仅击败了世界冠军,而且使用了没有人曾经做过的行为,我们关注人工智能即刻可触达的经济发展领域。
深度学习能力方面的主要飞跃成为当前进行中的 AI 拐点的催化剂。神经网络,深度学习之后潜在的科技架构,已经存在了几十年,但是过去的 5 到 10 年,三件事发生了改变。
1.数据。 通过分布于全球持续增长无所不在的互相联系的设备、 机器和系统产生的非结构化数据的数量呈现巨大的增长。拥有的数据越多,神经网络就变得越有效率,意味着随着数据量的增长,机器语言可以解决的问题的数量也在增长。移动手机、物联网、低耗数据存储的成熟和处理技术(通常在云端)已经在数量、大小、可靠数据结构方面创造了大量的成长。例如,特斯拉至今已经搜集了 780mn 英里的驾驶数据,并且每 10 小时通过它连接的汽车增加百万公里的数据。Jasper(2016 年 2 月被思科以 14 亿美元收购)拥有一个平台驱动机器和机器的沟通, 服务于多种汽车制造商和电话公司。 Verizon在8月进行了一次类似的投资,宣布收购 Fleetmatics,它通过快速增长的无线网络,连接运输工具上的远程传感器到云端软件。5G 的首次展示将最适当地加速数据可被获取和转移的机率。根据 IDC 的数字领域报告,到 2020 年,每年数据量将达到 44ZB(万亿 G) ,5 年内年复合增长率达到 141%,暗示我们刚开始看到这些科技可以达到的应用场景。
2. 更快的硬件。GPU 的再次使用、低成本计算能力的普遍化,特别是通过云服务,以及建立新的神经网络模型, 已经极大的增加了神经网络产生结果的速度与准确率。 GPU 和并行架构要比传统的基于数据中心架构的 CPU 能更快的训练机器学习系统。通过使用图像芯片,网络能更快的迭代,能在短期内进行更准确的训练。同时,特制硅的发展,比如微软和百度使用的 FPGA,能够用训练出的深度学习系统做更快的推断。另外,从 1993 年开始超级计算机的原计算能力有了极大发展 (图 2) 。 在 2016 年, 单张英伟达游戏显卡就有了类似于 2002 年之前最强大的超级计算机拥有的计算能力。 成本也有了极大的降低。 英伟达 GPU (GTX 1080)有 9 TFLOPS 的性能,只要 700 美元,意味着每 GFLOPS 只要 8 美分。在 1961 年,要提供1GFLOPS,需要足够多的 IBM 1620s 串联在一起,计算下来费用要超过 9 万亿美元(根据通货膨胀调整)。
3. 更好、更普遍可用的算法。更好的输入(计算和数据)使得更多的研发是面向算法,从而支持深度学习的使用。例如伯克利的 Caffe、谷歌的 TensorFlow 和 Torch 这样的开源框架。比如,刚开源一周年的 TensorFlow,已经成为****的开发人员协作网站 GitHub 上最多分支(或活动)的框架。虽然不是所有的人工智能都发生于普遍可用的开源框架中,但开源确实在加速发展,而且也有更多先进的工具正在开源。
方向
虽然本报告的重点是人工智能的发展方向以及公司如何把握这个方向, 但是了解人工智能对我们生活的影响程度也是很重要的。
在线搜索。 就在一年多以前, 谷歌透露, 它们已经开始将大量的搜索工作移植到了 RankBrain(一个人工智能系统) ,使其与链接(links)以及内容(content)成为了谷歌搜索算法的三个最重要的标志。
推荐引擎。 Netflix, 亚马逊和 Pandora 都在使用人工智能来确定推荐什么样的电影和歌曲,突出哪些产品。 5 月, 亚马逊开源了它们的深度可扩展稀疏传感网络引擎 (the Deep Scalable Sparse Tensor Network Engine(DSSTNE) ,简称「Destiny」 ) ,它被用于产品推荐,同时可以被扩展,以实现超越语言和语言理解的目的。
人脸识别。Google(FaceNet)和 Facebook(DeepFace)都投入了大量的技术,来确定照片中的脸和真实的脸是不是完全吻合。1 月,苹果采取了进一步措施,购买了 Emotient(一个致力于通过读取人的面部表情来确定其情绪状态的 AI 创业公司)显然,这些技术远远不止于对照片进行标记。虽然个人助理应用产品有无数的用户,比如苹果的 Siri,信用贷,保险风险评估,甚至天气预测。在接下来的篇幅中,我们探讨企业该如何使用这些技术来加速增长,降低成本和控制风险。 从这些技术及其使用这些技术的应用的发展速度来看,它们充其量不过可以为公司和投资者提供一些方向,以保持他们的竞争力。
价值创造的主要驱动力
经过深入分析,我们认为与 AI 主题相关的利润创造(和损失)可以分解为四个关键输入:人才,数据,基础设施和硅。这些投入也同时也是进入的壁垒。
人才
AI(特别是深度学习)难度很大。根据我们与领域中的风险投资公司和公司的对话,这种困难造成了人才短缺,以及大型互联网和云计算供应商对这类人才的竞争(见图 5) 。 对于 AI 人才的高度需求意味着获取必要的 AI 人才。 随着技术和工具的成熟, 人才可能变得不再是瓶颈。然而,我们相信人才会迁移到有趣的,差异化的数据集。因此,我们认为,当我们进入一个以 AI 为中心的世界时, 大的差异化数据集是最可能的提高和增加利润的驱动力。数据:数据是 AI 的关键输入。深度学习效果与大数据集紧密相关,因为更大的数据集会阻碍模型过度拟合。 例如, 来自马萨诸塞州总医院和哈佛医学院放射科的研究人员使用卷积神经网络来识别 CT 图像, 基于训练数据大小来评估神经网络的准确性。 随着训练规模的增大,精度将被提高(图 6)。
今天的大多数深度学习是监督的或半监督的, 意味着用于训练模型的所有或一些数据必须由人标记。无监督的机器学习是 AI 中当前的“圣杯” ,因为可以利用原始未标记的数据来训练模型。广泛采用深度学习可能与大数据集(这是由于移动互联网和物联网产生)的增长以及无人监督的机器学习的发展有关。然而,我们认为大型差异化数据集(电子健康记录,组学数据,地质数据,天气数据等)可能是未来十年企业利润创造的核心驱动力。
参考 IDC 报告,全世界创造的信息量预计到 2020 年将以 36%的复合年增长率增长,达到 44 泽字节(440 亿 GB) 。连接的设备(消费者和工业领域) ,机器到机器通信和远程传感器的增加和组合可以创建大型数据集, 然后可以挖掘洞察和训练自适应算法。 在过去十年中,数据的可用性也大大增加,人口普查,劳动力,天气,甚至基因组数据可大量的免费在线查询。
我们还留意到卫星图像的可用性增加, 这需要大量的计算来支撑全方位的分析。 美国地
质调查局的 Landsat 7 和 Landsat 8 卫星每 8 天对整个地球进行成像,USGS 使这些图像可以免费使用 - 即使是在压缩时,超高清图像的文件大小也各为 1GB 左右。其他公司,如Orbital Insights,正在汇总图像数据并在多个行业创建商业解决方案。
基础设施: 硬件和基础设施软件是开展 AI 工作所必需的。 我们认为支持 AI 的基础设施将被迅速商品化。这个观点基于两个现象观察:1)云计算供应商能够将他们的产品扩展到 AI基础设施中,2)开源(TensorFlow,Caffe,Spark 等)已经成为 AI 中软件创新的主要驱动力。为了促进 AI 技术的应用,我们认为大型云供应商将继续开放基础架构资源,这将限制利润创造的潜力。
硅技术:GPU 在深度学习领域的新用途成为我们目前 AI 春天的核心驱动力之一。在人工智能、机器学习生态系统中,存在二个主要应用来决定神经网络的表现,每个神经网络需要不同的资源。首先是学习算法的构造和使用。学习算法借助大数据(通常更大、更好)发现相互联系,并且创建模型,提供新输入,可以决定输出的可能性。学习是资源密集型,并且大多数现代学习通过 GPU 驱动的系统来运行。 一旦经过学习, 模型和算法的使用将被称为推论。推论需要更少的计算资源, 经常通过更小增量数量输入进行梳理。 一些 GPU 被优化用于推论(例如英伟达 P4 系列和 M4 系列) ,给出单目标的自然推论。硅谷有针对性地发展用于该应用的专业技术,例如 FPGAs(现场可编程门阵列)和 ASICs(专用集成电路) 。这种类型的集成电路被独创地用于原型机 CPU 中, 但是逐渐地被应用于人工智能推论。 谷歌的张量处理单元就是 ASIC 应用于 AI 和机器学习的一个例子。 微软也在将 FPGA 应用于推论。 英特尔在 2015年收购了 FPGA 制造商 Altera,有观点认为,到 2020 年,三分之一的数据中心将在特殊定制化应用中使用 FPGA。 赛灵思在 1980 年开发了可商业化的 FPGA, 领先提出了云和大数据将做为有价值的增长途径,宣布和百度达成战略协作关系。数据中心业务大概占赛灵思 5%的营业收入。
主要影响
促进未来生产力
在经历了 90 年代中后期的高速发展和过去十年的平缓增长后,美国的劳动生产力近几年已经进入了增长停滞的阶段。我们相信实用的机器学习和人工智能的蓬勃发展可以将生产力典范作用广泛推广至全球各产业领域。
人工智能和机器学习带来的自动化及效率提升在普遍各领域都缩减了约 0.5%-1.5%的
劳动工时,预计到 2025 年将带来 51-154 比特/秒的生产力提升。
在期待未来人工智能和机器学习得以同时提升生产效率的分子和分母(标准工时和实际投入工时),最重要的是它带来的早期影响将会体现在低薪工作的自动化层面,用更少的工时驱动同比产出增长。我们基本认为人工智能和机器学习提速 97 比特/秒意味着在 2025 年 IT将为生产率增长贡献 1.16%效能,也即比 1995-2004 提高 11 比特/秒。
技术与生产力增长
90 年代掀起的科技热潮伴随着生产力、资本深化和多因素生产力被异常放大,并与飞涨的股票估值紧密关联。
资本深化
高盛的经济学家 Jan Hazius 提供了他近期就资本深化(每工时资本量)反周期性趋势的分析, 在扩张时期没有同等水平股本增长的情况下历史劳动工时一般趋于增长 (参见 Jan 的报告: “生产率悖论 2.0 版本再探” 2016 年 2 月 9 日发表)90 年代资本深化急剧增长,其中最显著的是非典型资本投资的增长超越了劳动力市场的增长。
多因素生产力 (MFP)
2013 年 3 月,美联储研究的大卫 ・ 伯恩等研究后发现,90 年代在 IT 生产和一般操作流程中同时推广技术有助于促进增长呈三倍激增 (每劳动工时的产出) ,其中从科技热潮前到1995至2004之间, 年生产率平均每年增长中不超过49%的部分来自于IT 生产部门。 (展示 10)
千禧年后停滞期
在过去的十年中,有关 IT 应用 (计算机硬件、 软件和电信) 的资本深化增长已经停滞了。IT 资本,与更广泛的市场资本类似,带来 IT 部分整体增长相比科技浪潮甚至其之前的时期内还低。 总劳动时间一直在增加, 但资本强度对生产力的贡献已经远远落后于上世纪 90 年代。 日益精细且可利用的机器学习和人工智能可能成为一剂催化剂将资本密集度带回最前沿,在我们看来,将会带来类似 90 年代所看到的周期阶段,极大增加劳动生产率。对于方程另一侧的 MFP, 我们更乐观些。 高盛经济学家强调 ( “生产率悖论 2.0 再探” 2016年 2 月 9 日发表) ,ICT 价格的正偏差,非货币产出的输入增长 (免费的在线内容、 后端流程等) 也在一定程度上反映了实际 GDP 和生产力增长。Facebook 和谷歌等互联网巨头的发展充分说明了复杂输入的劳动力和资本并不必然将标准生产力指标中的传统消费品转换为货币。
人工智能/机器学习激发的生产力可以影响投资
我们认为人工智能/机器学习所带来日益增长的生产力产生的潜在影响之一可能是公司资本分配方式的转变。自 2011 年中期,股息和股票回购的增长大大超过了资本支出增长,然而管理层对于投资资本项目的冷淡依然保持了经济衰退后期的状态。生产率的提高有可能恢复管理层的信心, 并鼓励公司像上世纪 90 年代一样投资于生产性资本。根据高盛资本支出追踪,90 年代资本支出同比增长,持续性高于耶鲁大学教授罗伯特 ・ 希勒的 S & P 500 分析报告中的同比股息增长。我们有理由更相信投资者会支持提高生产率的这种转变。 在资本支出投资和相关生产率的增长期内周期性调整股价收益率经历了严重的通货膨胀,而目前的估值才刚刚达到经济衰退前水平。
AI 和生产力的矛盾:采访 Jan Hatzius
Health Terry: 是什么造成了过去 10 年可度量的生产力增长过低?
Jan Hatzius: 1990 年是一个生产力提升爆发点,主要原因是技术推动的。技术的变化和推进非常快,给我们经济的增长提供了非常强的动力。 然而在最近的十年, 这种生产力的增速降回了上世纪七八十年代,甚至比那时候还要更低。 我认为这种增长可以有多个推动点, 而不仅是技术。 但是我注意到有三件事降低了这种增速,第一件事是循环效应(Cyclical Effect),我们依然受制于经济衰退后持续的过低的资产化,过低的投资率和告诉的雇员数增长。因为我们的生产力是按照人时换算了,在劳动力市场告诉增长时,我们的生产力也就会越低。
另一个因素是技术增长的速度在放缓, 在九十年代, 互联网带来了一段时间的技术高速增长,但是现在看起来这种增速大大放缓了。 第三点是在过去十年发展起来的新技术,比如移动通信和消费者聚焦技术(Consumer Focused Technology),让统计学家们很难具体量化到数字,也就很难定量。这种新奇和聚焦某一个边界的技术对统计人员的要求越来越高, 但是统计人员还没有完全跟上脚步, 造成了统计错误。
Terry:回到 90 年代的生产力大爆炸,技术扮演了什么角色?
Jan: 半导体和计算机技术, 他们在经济结构中的比例比 70 和 80 年代高了很多, 而且统计学家们建立了好的计量规则。 他们在九十年代做了很多努力去更快实现新的生产力的度量, 比如处理器速度,更大内存,更多计算机硬件等。
Terry:在过去 10-15 年,我们也见到很多新技术的产出,比如 IPhone,Facebook 和云计算,但是为什么他们没有给经济带来同样的影响。
Jan:我们并没有确切的答案, 但是我认为度量能力的缺失是主要原因。 这些新产品对经济的影响比较有限。现在丈量名义 GDP 比较容易,在任何事物中都允许有丈量误差,但我不认为是在名义 GDP 的计量中出现了误差。将名义 GDP 按照各个事物的通货膨胀造成的定价变化转化为实际 GDP 才是最困难的部分。因为这些技术的发展都从通用的硬件转化为了更为专业用途的软硬件和数字结合的产品,这都给我们的度量造成了误差。
Terry:AI 和机器学习能对生产力提升造成什么影响?
Jan:现在看来, 这些新技术对生产力的贡献主要是在缩减成本和缩减劳动力需求, 这些对统计员们来说会比 iPhone 中的 app 对经济的共享更好统计。我必须要做出一个警告, 美国的经济规模非常大, 在任何一个小行业被 180 万亿美元做分母时都会使他看起来没那么大影响, 我们必须纠正这种观点, 这些细分行业存在对经济造成巨大影响的可能。
Terry:您刚才提到了成本,这些会影响定价吗?是否这为我们的通缩造成影响?
Jan:成本的降低必然带来定价的降低。 假如别的情况不变, 改变这个定价确实能降低定价和降低成本,假如别的因素都是恒定不变的话,这会带来一定的通缩。但是现实的市场经济是不会有静态的场景的,有规则的制定者会让人工智能等取代的工作的劳动力转移到别的工作上。我不认为长期上这种成本的降低会带来更高的失业率和更低的通货膨胀, 短期内可能会有这种现象。 规则的指定能够改变这种情况,总体上这些规则是为了维持一个非常稳定的失业率和通胀率。
Terry:有的观点认为,AI 和机器人自动化会取代劳动力,你认为这种观点合理吗?
Jan:我不认为这种情况会出现,人们确实有一些担忧,但是综合 19 世纪的例子,每一次技术的革新都会引起这种困扰。 最后人们在技术革新后还是找到了很多需要人去做的工作, 整体上我不认为会带来失业率的提高。
Terry:在过去的十年里,在投资市场里我们看到很多企业的回购和拆分。
Jan: 投资和生产力是息息相关的。近年来受制于经济大衰退,股票市场和投资市场都不景气,但是我们依然认为今年的投资率在慢慢上升,投资对生产力的影响也在提升,特别是在2010年和 2011 年。更多的机会是在细分的市场里。
Terry: 在企业利润上升的时候, 或者是发现新的利润点的时候, 获得的利润结合历史应该如何分配才能获得更高的收益呢?
Jan:从我对历史的研究中认为, 在企业获得新的利润点的时候, 可能短期内让企业的利润率飙升,但是很快就会有竞争介入,之后利润率就会恢复正常水平。
Terry:您觉得新技术如 Ai 和机器学习对资产的股价会产生什么影响?
Jan:过去一段时间,人们处于对于 90 年代技术快速提升带来的增长率的衰弱的恐惧,对股票的估值有了很大的变化。技术的高增长总体上会带来更高的估值。往回看 1990s,我们那段时间股价确实有一个高增长,但是周期结束后跌的也很惨。我认为肯定会对估值有很大影响。
生态系统:云服务,AI 的下一个投资周期开源的关键受益人
我们相信利用人工智能技术的能力将成为未来几年所有主要行业竞争优势的主要定义属性之一。 而战略将因公司规模和行业而不同, 那些不专注于领导人工智能所带来的最终的产品创新,劳动效率和资本杠杆风险的管理团队将被遗忘。因此,我们认为公司需要投资这些新技术以保持竞争力,将推动对人才,服务和硬件底层人工智能的需求的激增。
作为比较,20 世纪 90 年代技术驱动的生产力繁荣推动了相应的使能器的激增。对技术的资本支出推动了企业业务的增加, 来抓住这种资本支出。 在不可避免的行业整合发生面前,软件、硬件和网络公司形成都受到了影响。下面的图例 13 强调了软件行业内的这种模式,在 2000 年代中期巩固之前, 1995 - 1999 年期间,通货膨胀调整后近两倍的公共软件公司市值在 2 亿美元和 50 亿美元之间。
我们看到与 AI 驱动生产力的下一个周期相似的热潮, 随着企业投资利用 AI 的潜力, 在软件,硬件,数据和服务提供商上创造价值。如上文图表 14 所强调的,进入人工智能创业公司的风险投资在这十年中大幅增加,大大的反映了这一机遇。企业 AI 投资的热潮也开始推动整合。云平台特别是对 AI 的大量投资,谷歌,亚马逊,微软和 Salesforce 自 2014 年以来开展了 17 项与 AI 相关的收购。
比较 AI,ML 和历史进程中的其他技术阶段,我们能得出一些非常有意思的结论。在过去的五十年里, 计算力(摩尔定律)同事成为了技术进程的促进者和抑制者。 例如计算机系统市场 CS 架构开始的,近些年发展到了 cloude/mobile 模式。这种变化的一个因素是计算能力,存储和带宽的提升。同时每次还贷的变化都伴随着新的开发语言的演变。AI 和神经网络的概念和原型的提出是在 1960 年代,但是计算能力的限制让它直到今年才出现了实用的应用。我们依然处于 AI 平台的初期,就像 1950 年的主机系统和 2000 年的智能手机和云。这会带来应用,工具和服务的大爆炸。
AI 三个方向:自建,咨询服务和 AI 服务化
自建:有着大量私有高价值数据的公司会更喜欢在机器学习上投资。为了支持,出现了一大批开源可直接使用的 AI 栈上的组件,按照功能分层为(silicon,storage,infrastructure,software,data processing,engines,programming languages and tools)。产品和平台分别有Databricks,Cloudera,Hortonworks,Sykmind和Microsoft,Google,Amazon,Baidu提供
的平台等。
咨询服务:很多公司有自己的特殊数据集, 并会有需求为内部, 顾客和合作伙伴搭建 AI 服务。但是因为 AI 服务和计算能力现在是稀有资源,很多的专业服务商在搭建平台帮助人们获得这种计算能力。IBM 的 Watson group 正在做这件事。还有一些新入场的如 Kaggle。 AI 服务化:为了获取这种创新能力,很多企业会选择使用别的公司已经成熟的学习系统,而不是自己完全搭建。现在已有的是 Google 的 Clarifai 提供的图片 API。SalesForce.com也在提供基于销售数据的服务。
自建:云平台和开源系统正在成为 AI 的左膀右臂
通过和大量公司VC以及对世界五百强的访谈, AI/ML现在在互联网公司, 工业服务提供商(如Board Institute)中应用非常多。
阻碍企业应用 AI 的主要障碍是数据和人才。随着企业通过物联网,机器和顾客数据或者还有外部数据服务的改进, 数据障碍正在逐渐扫清。 越来月的多毕业生还有通过培训获得了AI 相关只是和技能的人在填补人才的障碍。随着这些趋势,我们认为越来越多的公司会开始使用机器学习。
因为是从无到有来创造的,现在 AI 相关的技术栈仍然是非常碎片化的。欣慰的是整个AI Stack 正在逐渐形成,现有的创新蓝图如下,具体覆盖了存储,工具,语言等各个层面,依然有非常多的创新等着我们。
和之前的技术的一大区别是 AI 技术非常依赖开元和云平台技术。数据量非常大,计算能力贵,幸亏几大公司已经在开始提供这些服务,能够降低费用。
对 GPU 计算能力的需求是现在的 AI Spring 发展的一大诱因。在 AI/ML 系统中,有两个主要应用决定了整个神经网络的能力,这两个应用都有各自需求的资源系统。第一个是training algorithm,它在大量数据中寻找出关系,并提炼出模型,并通过模型决定对应新输入可能产生的输出。训练对资源非常敏感,多数的训练是在基于 GPU 的计算系统上。
训练出的模型和算法被称为 inference. Inference 对计算能力的要求会低很多,并且多数是在更小的不断增加的数据中梳理出来的。FPGAS 和 ASICs 等是已有的相关架构,但是这些是在 CPU 计算能力的基础上搭建起来的。Google 的 Tensor Processing Unit 是一个 ASIC结构的具体实现。微软使用 FPGA 也有一些实现。INTEL 等也在 FGPA 等方面在做一些具体的应用。
考虑到搭建 AI 系统的投入和产出,我们认为只有少数公司会选择自己搭建自己的专用系统。多数公司会选择使用公共提供的服务,这也促使了入 Databricks 等开源服务提供者的出现,这些服务会成为多数公司的****。
下面列了一些具体的基于 GPU 的云服务提供商的不同的特点, 可以作为选择哪个服务的参照点:
Amazon AWS:纸面上看起来是现在最强大的。自大提供 64 核 CPU,16 Tesla K80 GPUs,
732GiB。内存,价格是 6.8 美元每小时。
Micorsoft Azure:现在仍然是在预览阶段,24 cores, 4 Nvidia Tesla K80 GPUs, 224
GB of memory and 1.4TB SSD disk。
Google Cloud Platform(GCP):Beta 阶段,
Alibaba:只是透出来消息和 Nvidia 在合作使用 Tesla K80 GPUs.
存储:在深度学习中, 大量的数据能够为学习模型提高能力。 考虑到成本和已有的 HDFS 还有S3 等存储结构的成本,还有 EMC 等物理机器的成本。现在数据的增速太大太快,选择开源的存储结构和公共服务存储的同时或者相关的技术支持比自己搭建专用的整套系统更为合适。
消息,流处理和数据转化是机器学习的关键组件。在模型的训练过程中,数据是作为流被传入存储系统中的,并在进入神经网络前经过加工。一旦模型被建立,来自传感器,网站和其他来源的活数据被流进模型进行分析,然后试试分析这些数据。在以前的 ETL 提供商(Informatica 和 IBM)还有消息厂商(TIBCO)提供了一些流提供和流处理技术。 在过去的五年时间里,开源技术入 Kafka,Storm 和 Spark 被越来越广泛使用,还有消息服务如 Amazon Kinesis 和 Google Pub/Sub。
在神经网络中,数据是需要做预加工的。比如,图片和文本要被转化为相同大小或者颜色,或者格式。使用 SkyMind 的 DataVec 等工具,可以通过编程实现这些加工。
可参照的公司:
Confluent (Kafka), Databricks (Spark Streaming), Cloudera (Spark Streaming),
Hortonworks (Storm, Spark Streaming), Amazon (Kinesis), Google (Cloud DataFlow),
Skymind (DataVec), IBM (Streams), Microsoft (Azure Data Flow).
数据处理:数据库和数据处理技术一直是一个大市场,2015 年统计,数据库市场规模是$35.9bn。****的公司是 S&P。在 AI 应用中,神经网络成为了一种关键的数据处理技术,神经网络从节点获取数据,然后产生输出。例如,输入可能是图片或者是邮件,输出可能是“spam” 或者 “cat”.
已有的神经网络的具体实现有 Google TensorFlow or Caffe,能够帮助用户直接使用这些服务处理数据。
在很多公司里 Spark 的应用已经比较广泛,发展也最快,应有超过10个 Github 星级项目,并获得了来自 IBM, Cloudera, Hortonworks and Databricks (which has the bulk of the committers to the project)的投资。
编程语言: 现在编程语言的支持仍然是在非常初级的阶段。 现有的用的最多的语言是 Python和 R。R 应用中 Microsoft (which acquired Revolution Analytics) and RStudio (an open source provider)是主要的支持者。
分析工具:非 AI 行业相关的数据加工的工具,比较成熟的是 SAS Institute and SPSS, BIsolutions such as Microstrategy and Business Objects,报表类的有 Crystal Reports。最近商业应用中 Tableau 提供的数据可视化服务也比较火。
机器学习相关的工具,如 Microsoft’s Azure Machine Learning solution,为使用者提供了一种直接拖拽的界面,SAS 也提供了界面化的操作工具。
可关注的工具:
SAS (SAS Enterprise Miner), Tableau, Microsoft (Azure Machine Learning), Amazon (Amazon Machine Learning),
Google (Cloud Machine Learning), Databricks
咨询服务
已有一些咨询公司提供相关的服务,来解决人才的问题。已有的提供相关服务的公司有: IBM, Accenture and Deloitte,Teradata.
在机器学习相关人才的培训和储备上,现在做的最好的是这几家公司:
IBM, Huawei, Accenture and Deloitte
Appirio, Bluewolf, and Fruition Partners 这些云计算相关的公司也在人才储备方面增长明显。
表 21:AI-aaS 产品及定价
云平台 AI-aaS 产品示例
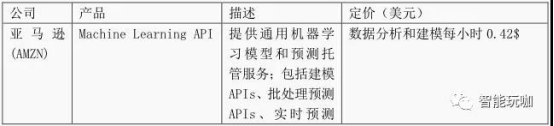
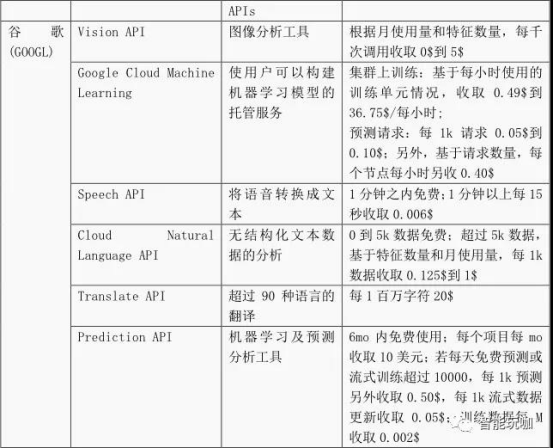
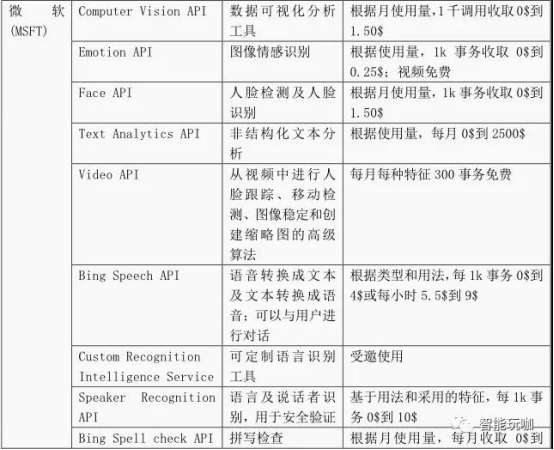
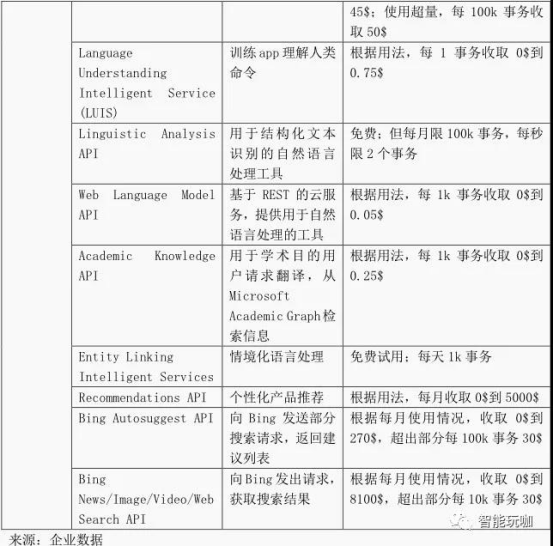
AI 服务化
细化的基础行业 AI-aaS 情况(客户流失,员工保留等)
在更加细化层面,例如:CRM(商机分析) 、HR(人才保留)和制造业(预见性维护) ,可以看到 SaaS 供应商已经开始布局, 这主要得益于 SaaS 供应商可以接触到大量的不同种类的数据。 Workday, Salesforce.com, Zendesk, Oracle, SAP 和 IBM 是最终能够角逐细化的 AI-aaS市场的几家供应商。我们调查过的大部分 SaaS 供应商都在开发数据分析产品和建立基准数据集,并且我们发现他们的数据长远来讲是一种障碍。 (并且我们发现这类供应商已经为长远发展而圈地)。
Salesforce 在机器学习能力积累方面步伐****,其在过去 18 个月中有过 4 次 AI 类型公司的收购(见图 5) 。
考察的公司包括:
IBM, SAP, Oracle, Salesforce, Workday, Zendesk, Hubspot, Shopify, Ultimate Software, ServiceNow
垂直专业行业 AI-aaS 情况(医学图像处理、欺诈预测、天气预测等)
垂直特定领域的“AI 即服务”很可能更多样化地推动。大产业巨人能聚合数据,通过这些数据可以构建机器学习模型,同时可以将这些模型卖给合作方、客户、供应商。初创公司可以在垂直领域的用例中构建独特的数据集, 例如医疗影像, 可以使整个医院网络有其可访问的接口。 各领域的行业协会, 例如零售或广告业能混合数据(术语)使其和更大的竞争对手竞争(例如一些零售商能够通过混合数据更好地和亚马逊的推荐引擎竞争)。
医疗行业中,IBM 在开发垂直特定的 “AI 即服务”的能力已经是一个佼佼者。近两年IBM 已经花费超过 40 亿美金来获得大量的医疗技术和收购数据公司。这些收购的结果是大
量的医疗数据(IBM 在其“健康云”有超过 3 亿病人的医疗记录) 。用这些医疗数据(包括通过合伙企业所采集的其它数据)和他沃森技术的集合,IBM 正在向肿瘤学、临床试验、基因组等用例(场景)提供服务。 在医疗垂直领域, 其它的初创公司也正在遵循类似的方法来解决医疗影像、药物发现、诊断等方面的疑难问题。
医疗行业的垂直“AI 即服务”展示:
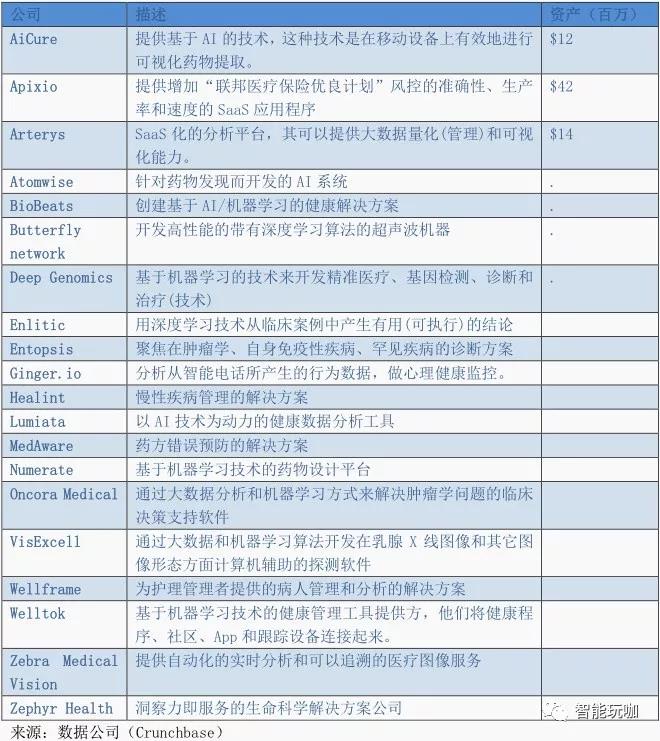
中国人工智能现状
根据 IResearch 的研究,中国 2020 的 AI 市场规模将由 2015 年的 12 亿人民币增长到 91 亿人民币。在 2015 年,有将近 14 亿(年同比增长 76%)的资金流入 AI 市场。在政府政策方面,中国发改委联合相关部门在 2016 年 5 月 18 号发布了互联网+和人工智能三年实施计划。规划确定了在六个具体方面支持人工智能的发展,包括资金、系统标准化、知识产权保护、人力资源发展、国际合作和实施安排。规划确立了在 2018 年前建立基础设施、创新平台、工业系统、创新服务系统和 AI 基础工业标准化这一目标。发改委预计中国的 AI 工业会和国际发展水平接轨,同时在系统级的 AI 技术和应用方面领先世界市场。中国已经采取了行动:从提到“深度学习”或者“深度神经网络”的期刊文章数据上看,中国已经超越美国。中国的 AI 研究实力同样让人印象深刻,其拥有********水平的语音和图像识别技术。百度在 2015 年 11 月开发的深度语音 2 可以达到 97%的准确度,并被 MIT 科技评论评为 2016 年度十大科技突破。另外,早在 2014 年中国香港大学开发的DeepID 在LFW数据集上达到了 99.15%的准确度。
中国互联网巨头 BAT 引领中国 AI 的发展, 与此同时, 数百个初创公司在不同的 AI 细分和应用领域建立服务模型。当前,中国的 AI 市场主要分为以下几个领域:
1) 基础服务如数据源和计算平台
2) 硬件产品如工业机器人和服务机器人
3) 智能服务如智能客服和商业智能
4) 技术能力如图像识别和机器学习
根据 iResearch 的报告,语音和图像识别分别占有当前中国 AI 市场的 60%和 12.5%。71%的中国 AI 公司集中在应用开发上,其他的则聚焦在算法上,其中 55%是计算机视觉,13%在自然语言处理,9%在基础机器学习。
我们认为,未来 AI 领域的引领者仍将会在美国和中国。
机器人:用户界面的未来
机器人是非常具有潜力的范式转换。 在以机器人为中心的世界, 用户体验从基于点击的行为转向会话(文本或者语音)以及互动从网络或面向应用转向消息或语音平台。 换句话说, 相比之前的打开三个不同的应用程序分别预约旅行, 购买衣服以及参与客户服务, 而现在用户只需要通过会话提供信息给提供帮助的机器人,从而完成同样的事情。因此,我们能看到这些对电子商务,客户支持,员工工作流程及工作效率的广泛影响。
在最近的 12-18 个月中, 一个关键驱动因素是大型云服务和互联网公司建立并开放了机器学习框架。在 2015 年年末,Google 开源了机器学习算法库 TensorFlow,亚马逊和微软在这方面也非常活跃, 通过提供云服务支持他们自己的机器学习项目。 我们预计这种机器学习平民化的趋势将会持续激发智能机器人的发展,主要领导者(亚马逊,谷歌,苹果,微软)期望整合会话界面(Alexa,GoogleAssistant,Siri,Cortana)到他们的各自的生态系统。 继今年三星收购 Viv,我们预计将在三星设备和智能手机生态系统中进一步整合基于 Viv AI 的数字助理。
自然语言处理(NLP).机器人的期望植根于他们智能或处理自然语言的潜力。 因此伴随着机器学习、自然语言处理的人工智能技术、计算机理解、以及语义理解兴趣和创新的兴起,对机器人的兴趣也在兴起。相比过去的文字处理方式,与基于硬编码规则集构建的 CTRL+F 函数操作的处理器相反,NLP 利用机器学习算法来基于海量训练数据来学习规则,然后可以将其应用于新的文本集。机器学习的核心原则同样适用于 NLP,获取的数据越多,其应用程序就越准确和更广泛。
虽然 NLP 的早期应用已出现在文本挖掘(例如,法律分析文档,保险单和社交媒体)和自动问答中, 但是神经网络和深度学习模型的优势正在使 NLP 变得越来越智能化, 解决人类语言的歧义问题。 Google基于人工智能系统Tensorflow的自然语言解析模型分析库SyntaxNet,SyntaxNet 将神经网络运用于歧义问题,一个输入句子被从左到右地处理,只有当存在多个得分更高的假设的时候,一个假设才会被抛弃。SyntaxNet 模型是谷歌的 TensorFlow 框架训练过的最复杂的网络结构。
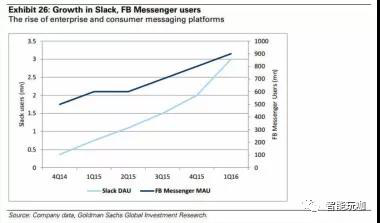
消息平台.机器人的兴起与诸如 FacebookMessenger,WhatsApp 以及面向企业的 Slack 和HipChat 等消息应用的快速增长同步。消息应用程序提供了一种媒介,通过它,机器人可以与 iOS,Android 和网络上的用户进行交互。此外,更大的消息应用正在发展成支持多种交互类型的平台。在 Slack 上,企业用户可能与团队合作,监控应用程序,创建待办事项列表或从同一接口监控费用。 FacebookMessenger, 能够利用同一个界面, 用户可以与朋友聊天,提出品牌的支持问题或进行 Uber 预约。
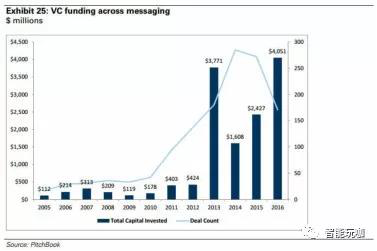
最近的聊天机器人收购或亚马逊(Angel.aiCEO)和 Google(API.ai)的部分收购,每一个都专注于会话界面技术, 突出了公司和投资者在聊天和自然语言处理能力的联合中看到的机会。根据 Pitchbook 的数据,自 2013 年以来,在 AI/ML,电子商务,SaaS 和网络安全等方面的私人消息公司累计风险投资约 120 亿美元,而在 8 年前则约为 20 亿美元。
事件机器人的广泛应用已经使得一些公司获益良多。 第一大类的获益的公司是信息传播平台,例如 Facebook,Slack,WeChat 等等。机器人帮助推动用户参与度的提升,创造机会驱动平台上的商业活动。第二大类获益的公司是硬件和基础设施提供商,其范围从 GPU 提供商(NVIDIA)到开源提供商,到数据平台提供商,以及像亚马逊,谷歌,微软这样的云服务提供商。其中,亚马逊位置独特,它具有满足电子商务需求的能力。另外一些正在挖掘机器人能力的软件公司包括 Zendesk 和Salesforce.com,它们把机器人看作是自动化满足企业客户需求的一种潜在方式。
数字个人助理。很多公司一直在使用复杂的算法,机器学习和大数据软件构建推荐引擎,这些推荐引擎的背后是对客户数据以及历史行为的全面分析。 这些推荐引擎正在用于影响购买行为, 但大部分相同的技术是用于构建数字个人助理, 或者能够基于语音命令完成或自动化简单任务的机器人。
通过融合推荐引擎的复杂预测和推断能力, 同时结合语音识别软件, 很多公司推出了自己的数字个人助理产品,例如, 苹果的 Siri,亚马逊的 Alexa,谷歌的 Google Assistant,微软的 Cortana。利用机器学习和云端基础设施,这些应用程序在收集更多的用户信息的同时不断改进,这些用户信息包括:语音模式,兴趣,人口统计,消费习惯,日程,职业,喜欢和不喜欢。大多数(如果不是全部)这些信息通常可以通过软件监控一个人的智能手机或连接设备(Amazon Echo,Google Home)来收集。随着这些数字个人助理接触到更多的数据,通过深入分析它们能够区分来自不同用户的类似请求,从而越来越个性化。例如,语音指令 “给我看最好的相机” 对不同的消费者可能意味着不同的东西。 与用户数据相结合的强大分析引擎可以帮助确定用户是否喜欢******的摄像机, 最高评价的摄像机, 或者通过各种特征组合筛选出来的对于该用户“****”的摄像机。
我们看到数据聚合和分析持续推动了人工智能驱动的数字个人助理的改进。 我们也期待像亚马逊,谷歌这样的持续创新者能够继续完善在购物过程中的使用体验(Echo,Echo Dot),从而更加深入到日常生活中的各种任务当中(Google Home)。
人工智能生态
人工智能的关键参与者
人工智能生态:使用案例与潜在机会
农业:目标时长 200 亿美元
◆优化种子种植、施肥、灌溉、喷洒和收获
◆ 对水果和蔬菜进行分拣,以降低劳动成本
◆ 根据声音的变化识别牲畜是否生病
金融业(美国) :每年节约和新增收入 340-430 亿美元
◆ 在财务数据冲击市场之前识别和执行交易
◆ 正和包装卫星图像,用于经济、市场预测(如石油库存和零售交通的图像)
◆ 识别信用风险并自动设限、关闭可能违规的账户
◆ 监控电子邮件
医疗:每年减少支出 540 亿美元
◆增加新药成功率
◆ 通过历史数据分析改善护理算法
◆ 降低程序成本
零售业:每年节省 540 亿美元,新增 410 亿美元收入
◆ 基于图像的商品搜索
◆ 通过大数据增强推荐引擎功能,设置销售、库存和用户偏好
◆ 改善在线搜索提升客户支持
◆ 商品需求预测和定价优化
能源领域:累积节省 140 亿美元
◆ 学习地质和生产数据,进行项目识别和规划
◆ 提高设备可靠性,减少厂井冗余
◆ 减少下游行业设备的维护停机时间
行业应用
农业
到 2025 年将达到 200 亿美元的潜在市场总额(total addressable market,TAM)
我们相信机器学习 (ML) 在以下方面具有潜力: 提高农作物产量, 减少化肥和灌溉成本,同时有助于早期发现作物/牲畜疾病,降低与收获后分拣相关的劳动力成本, 提高市场上的产品和蛋白质的质量。当我们看到用于收集土壤,天气,航空/卫星图像,甚至听觉数据的传感器的扩散,我们认为,从这些 PB 级数据,深度学习算法能帮助洞察(或者是制定)种植时间、灌溉、施肥以及畜牧相关的决策,最终增加农业中土地,设备和人的生产效率。鉴于所使用的所有已确定的技术数字农业将被优化或完全由机器学习和人工智能驱动, 我们假设 25%的价值创造会累积到机器学习和人工智能的产业链,这将意味着在 2050 年 1.2 万吨农作物市场中的 600 亿美元的潜在市场总额,假设在该时间段内线性分摊,意味着到 2025年潜在市场总额大约为 200 亿美元。
机会在哪里?
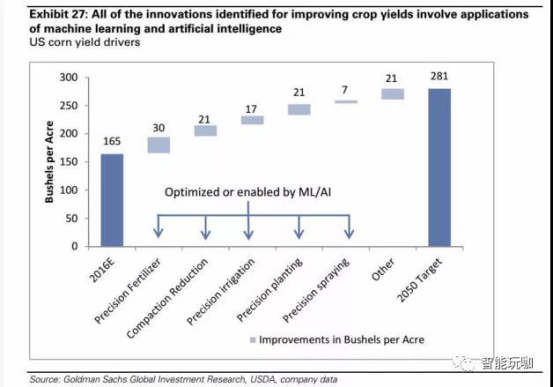
将机器学习应用到农业中会显著地减少产量损失与劳动力成本。 仅就美国玉米生产而言, 我们的权益研究团队已经确认从精确施肥到压实减少等一系列技术,他们认为到 2050 年可以将玉米产量提高 70%。重要的是,在他们的研究中确定的每一个创新都是由机器学习和人工智能实现的(图 27)。
我们已经确定了农业中的几个具体领域会特别受益于机器学习和 AI 技术的应用。 例如,农民商业网络,这是一个汇总关于种子性能,农艺实践,投入品价格,产量基准和其他农民提交的数据的组织,以利用深度分析来提高产量。
利用传感器,天气,土壤,甚至无人机/卫星图像数据,机器学习可以根据当前和预期的天气模式,作物轮作对土壤质量的影响,帮助农民优化施肥,灌溉和其他决定,确定****生产模式。 空间图像分析可以比人类观察更快更有效的帮助确定如大豆锈病这样的作物疾病, 更早介入以防止产量损失。
相同的模式识别技术可以用于在家畜动物中识别疾病和跛足 (影响运动和健康的腿/脚/蹄的感染或损伤) 。最后,我们看到了使用视觉图像和自动分拣设施来替代产品和肉类分级和分类线上目视检查员的应用。
痛点在哪里?
农作物产量受不理想的施肥,灌溉和农药使用的负面影响。高盛研究报告“精确农场:用数字农业欺骗马尔萨斯” (Precision Farming: Cheating Malthus with Digital Agriculture 2016年7月13 日)中,确认了几个问题,这些问题可以通过收集适当的数据和执行适当的分析来解决。 这是至关重要的,因为到 2050 年,为给世界人口提供足够的粮食需要增加 70%的粮食产量。
人力成本增加。 农业已经历史性的转向用技术创新抵消劳动力成本, 我们认为机器学习是这一演变的下一步,特别是在收获/屠宰之后的分拣过程中,其中大多数对产品和肉制品的目视检查仍然由人类工作者完成。根据劳工统计局 BLS,5.3 万人在美国受雇为“分级分拣农产品” ,每年产生大约 13 亿美元的劳动力成本。 根据 BLS 数据,农业中的“农药处理,喷雾器和施药器使用者”另外产生 13 亿美元的劳动力成本。由动物疾病造成的损失。我们估计,由于乳牛跛足,全球乳品业的年损失超过 110 亿美元,而这是可以提前预防的。学术研究表明,在乳汁流失,生育力下降和治疗成本之间,每一例跛足会使乳牛场产生成本 175 美元,而平均每年 100 头奶牛中会发生 23.5 例跛足,这意味着全球 2.5 亿头奶牛每年会产生 110 亿美元的损失。
目前的经营方式是什么?
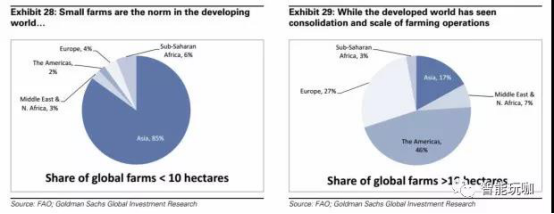
绝大多数农场都很小,但大多数农田是由大型农场控制的。 根据联合国粮农组织报告,全球 72%的农场面积小于 1 公顷,而所有农场中只有 1%的农场大于 50 公顷,这些大型农场控制着 65%的全球农业用地。 超过 10 公顷的农场绝大多数存在于像美洲和欧洲这样更发达的地区(这两个区域占总数的 73%) ,而亚洲占小于 10 公顷的农场的 85%。 因此,世界上大多数农田都能获得基础设施和经济发展, 能够使用精确农业技术, 只要这些技术是财务上可行的解决方案。
即使在经济发达国家,精确农业仍处于早期阶段。 例如灌溉,仍然通过溢流或其他形式的表面灌溉进行,这是效率最低和技术最落后的方法之一。在作物种植的主要领域,目前的技术包括:
肥料:天气和现场监测,和农业盖毯应用。
种植:多种子种植机,可变速率种植和作物轮作。
农药/除草剂: 卫星和无人机图像已经在一些规模化经营中针对大范围目标区域使用。较小的使用在农业盖毯领域。
灌溉:溢流和其他表面灌溉,中心枢轴洒水器,滴灌系统和喷淋/滴灌混合系统。
收获/分拣:玉米和小麦等作物的大部分收获已经开始在大农场机械化。一些分类已经自动化(按大小和颜色)通过在美国建立农民商业网络(FBN) ,我们还看到农业数据民主化的到来。FBN 是一个独立的业务,农民可以订阅并匿名的提交农场数据。在分析过程中,FBN 使用聚合的农场数据为单个农民成员提供如何确定产量,时间,天气和其他数据的建议。在畜牧业和乳制品业中, 目前的技术包括普遍使用抗生素或其他预防性药物, 接种疫苗,扑灭病动物,以及化学平衡的饲料添加剂。此外,牛的饲养也采用足浴以预防和治疗蹄类疾病和感染。
图 30:在美国,接近一半的农业灌溉用地是通过浇灌或其他的地面灌溉方式被灌溉的。地面灌溉是一种效率最低、技术最落后的灌溉方式。
下图显示按照不同灌溉方式进行灌溉的农业用地的百分比。
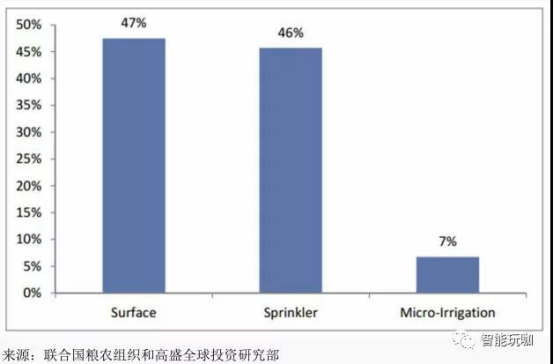
人工智能和机器学习能起到什么作用?
机器学习所具备的通过使用大数据集来优化单个或一系列关键目标的能力很适合用来解决农业生产中的作物产量、疾病预防和成本效益等问题。
在农作物产后分拣和农药应用领域, 我们认为随着时间推移仅在美国境内机器学习和人工智能技术能通过降低成本和提高效率每年节约 30 亿美元的劳动力成本。 按照我们的估计,全球范围内的这个数据极有可能超过美国所节约成本的两倍。 最后, 我们认为机器学习和人工智能技术能改善育种和牲畜健康状况, 并且能在奶牛养殖领域创造出大约 110 亿美元的价值(即对失去的潜在收益的补偿和节约的绝对成本) ,以及能通过两种常见疾病的控制在家畜养殖领域创造出 20 亿美元的价值。
提高作物产量。人类已经利用了地球上几乎所有可用的农业用地,然而联合国预计到 2050年全球人口将达到 97 亿。因此,为了满足未来全球对粮食的需求,我们非常有必要提高农作物产量。机器学习技术可以被用来分析来自无人机和卫星图像、气象模式、土壤样本和湿度传感器的数据,并帮助确定播种、施肥、灌溉、喷药和收割的****方法。
图 31:机器学习技术在我们于 2016 年 7 月 13 日发布的《精准农业》报告(参考文献 1)中所确定的每一项创新中几乎都发挥着重要作用。
下图显示不同技术所带来的玉米产量的潜在提高量。

收获后分拣劳动。 在一个简单的案例中, 我们发现 Google 公司的 TensorFlow 机器学习技术被日本黄瓜菜农用来自动分拣黄瓜, 而以前分拣黄瓜的程序一直需要大量手动或视觉检查工作和劳动力成本。在这个案例中,农夫只需使用包括 Raspberry Pi 处理器和普通网络摄像头在内的简单又便宜的硬件设备,就能用 TensorFlow 训练出一个能将黄瓜分成 9 个类别并且具有相对较高的准确度的算法, 从而减少了与分拣相关的劳动力成本。 我们认为相似的应用可以扩展成更大的规模, 并且被用于具有较高分拣需求和成本的农产品, 例如西红柿和土豆。
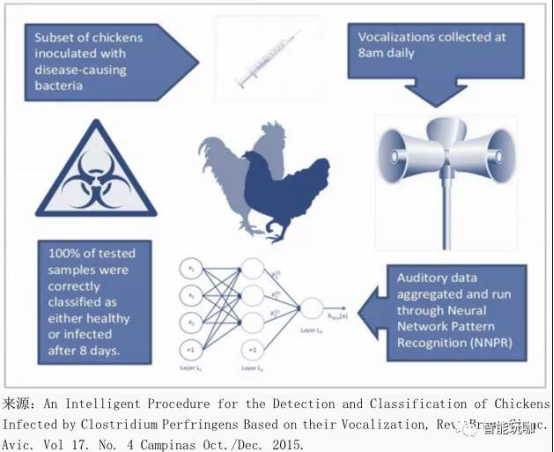
家禽种群中的疾病监测。 在一项学术研究中, 研究人员收集和分析鸡的声音文件并假设在生病或痛苦的情况下,它们发出的声音会改变。在收集数据并训练神经网络模式识别算法后,研究人员能够正确地识别出感染了两种最常见的致命疾病之一的鸡, 其中发病 2 天的鸡的识别准确率为 66%,而发病 8 天的鸡的识别准确率为 100%(如图 32) 。正确诊断牲畜所患疾病并尽早在损失发生之前进行治疗可以消除由疾病导致的损失。 据行业专家估计, 挽回的损失可达 20 亿美元。
图 32: 实验表明, 机器学习可以通过音频数据分析来正确识别用其他方法不可检测的疾病,几乎能消除由于某些可治愈疾病所引起的损失。
量化市场机会
基于农作物产量、 作物投入成本节省、 乳品/畜牧成本节约、 分拣和劳动力节约的潜在增长,我们认为机器学习技术的应用能创造超过 1 万亿美元的价值。
在农作物种植领域,我们认为机器学习和人工智能技术可以帮助实现农作物产量提高70%。在 Jerry Revich 所作的关于精确农业的表述中(参考文献 1) ,假设各种技术供应商的价值增值幅度为 30%,数字化农业的潜在市场总额可达 2400 亿美元。考虑到数字农业中使用的所有已知技术将经过机器学习和人工智能技术的优化或完全由其提供, 我们假设所创造的价值的 25%由机器学习和人工智能技术链中的供应商累积, 这意味着机器学习和人工智能技术在作物种植应用中的潜在市场总额为 600 亿美元。 在蛋白质类农产品领域, 我们认为机器学习技术的应用(例如精确育种机制,疾病预防和治疗)可以催生另外 200 亿美元的市场。
参考文献:
1. Jerry Revich et.al, “Precision Farming: Cheating Malthus with Digital
Agriculture,” published on July 13, 2016.
哪些行业会受到影响?
根据机器学习为灌溉、施肥、劳动力和疾病预防治理成本带来的节省,我们相信机器学习有潜力在低成本的基础上扩大全球的粮食、乳制品和牲口的供应。
由于机器学习的应用可以限制废料并且改善农业预防措施, 我们预计以下行业的全球市场会引起波动:化肥业,除虫剂业,除草剂业,除菌剂业以及兽医药业。
我们相信大部分此类波动会是相当长期的(五年以上) ,由于我们现在都还处在这些机器学习技术的早期, 所以相对其他技术, 机器学习技术目前对以上行业人士可能还无法承担。
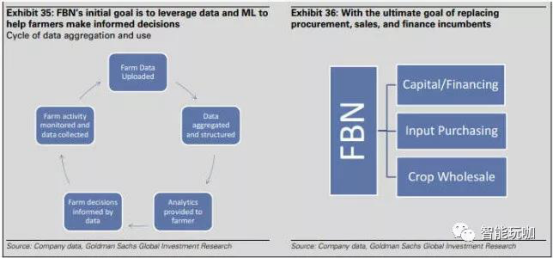
农民商业网络 (Farmers Business Network)
我们访谈了 Amol Deshpande,他是 Farmers Business Network(FBN,农民商业网络)的联合创始人和 CEO,同时也是该公司的工程团队成员。FBN 的网络有超过 2800 位农民,覆盖了超过 1000 万公顷的农田,这样做可以让农民和农场总结和上传数据,进而使得农场数据可以更加大众化,并且使农民可以利用数据定价、先把种子和优化产量。
存在问题
由于在农业组织内部的信息不对称,当农民在制定关于种子选择、肥料选择等决策时,不知道哪个品种在该区域的产量在近年内****化, 甚至不知道该价格是否相对其他农民有可比性。农民也确实曾经被供应商区别对待。
FBN 解决方案
数据整合与分析: 农民可以每年给 FBN 缴 500 美金作为会员费。 然后农民可以从他们的设备和系统将数据上传,包括种子品类、土壤、产量以及地理信息。FBN 也会从其他的公共渠道收集到政府和天气方面的信息。FBN 运用机器学习技术对数据进行语法分析,然后清洗数据并且分析数据, 进而为农民提供意见, 或者定制给单独的农场去帮助他们选择最优的输入以及策略,进而****化产量和生产率。
筹措资金:FBN 也尝试从事专属金融业务,利用从农场获得的历史和预测数据对信用进行评定。在没有信用检查的情况下,FBN 已经对剩余还款计划可以达到 97%以上的还款率。进货:由杀虫药开始入手,FBN 已经开始为该网络的农民提供进货服务。基于 FBN 的海量价格信息以及代表千千万万农民采购的能力,FBN 相信它可以谈到更好的价格并且降低成本,同时每比交易获得 9%以上的成本。开始几个月每个订单的数额可以达到 4 万 5 千美金。
零售
预计 2025 年,将减少 540 亿美元成本,并增加 410 亿美元额外收益消费者的线下转线上已经给传统零售行业提出了很大的挑战, 电子商务出现的同时, 也为零售商提供了大量的消费者数据。 但是, 零售公司应该如何利用手中积累的数据来为消费者提供更好的服务,获取更多利润,这个最重要的问题依然没有得到解决。早期,成功尝试利用这些数据的企业,是通过线上广告技术来更加有效地定位网络上的客户。现在,零售商能够利用不相关的数据集,不仅仅能够优化广告,更能做到优化库存管理、需求预测、客户管理和趋势预测。我们发现 AI/ML 可以推动这方面的进步,通过需求预测,可以推动每年价值 540 亿美元的劳动效率提升。预计 2025 年之前,通过优化定价将在全球范围内实现任意品类,比如服装和鞋类等,超过 410 亿美元的年度销售额提升。
机遇是什么?
进入千禧年之后,零售行业亲历了重大变革,随着消费能力的提升,消费者的购买习惯也开始逐渐向线上化进行转变。尽管零售商为了应对这些变革已经做出了一些成功的改变,但是 AI/ML 可以给全渠道零售商和单一业务的零售商提供从大量消费和产品数据, 使其能够从中洞察商机。用户消费所产生的数据也逐渐转到线上,支持不断积累和技术进步。在我们的研究中,也发现了一些可以利用 AI/ML 来拓展零售价值链的关键领域。
虽然推荐引擎在电子商务领域中不是一个新鲜事物, 但传统技术面临着一些限制, 我们认为 AI/ML 流程可以超越传统技术,从销售和内容数据中提取更深入、更准确的见解。与此同时,自然语言处理(NLP)AI 系统可以实现更直观且相关性更强的搜索能力,以及对话式商务能力。此外,将 AI/ML 整合到批发和零售采购的早期和后期阶段,可以通过更精确的需求预测提高劳动力和库存效率,并通过优化定价改善销售。
痛点是什么?
预测需求,趋势。零售面临的****挑战之一是如何恰当的引导趋势以及衡量需求。特别是在服饰方面, 设计师和买家通常会在物品到达货架前两年做出关于什么是时尚和需求的决定。目前的预测模型在自动化、解释需求驱动以及历史数据的限制等方面展现出不足。
库存管理。 由于价值链各部分之间的系统复杂程度和协调水平往往是不同的, 库存管理仍然是一个难题。 库存过剩和缺货都可能对零售商的销售产生重大影响, 因此库存管理在整条价值链中显得至关重要。IHL 的一项研究显示,截至 2015 年第一季度,超过 630 亿美元的销售损失是由缺货造成的,超过 470 亿美元是由库存过剩造成的。
商店的数量和规模。商店的遍布(footprints) ,不管是从总面积还是人均使用面积来看,一直都是零售商的痛点。2015 年,美国的零售店的总面积为 76 亿平方英尺,人均使用面积 23.5 平方英尺。而 2005 年分别为 67 亿平方英尺和 22.8 平方米(图 55) 。随着电子商务不断渗透到如电子和服装这些传统类别,新的类别如快速消费品(CPG)将为电子商务提供新的增长点。

目前的业务如何开展?
目前业务的开展方式可以归纳为由生产、 仓储、 分销和零售这 4 个步骤组成的一条价值链。虽然这四个步骤展现了业务的一般开展方式,但是在每一个步骤中,通常都可以找到附加步骤, 合作伙伴或中间人。 如果将制造到销售的过程进行合并, 可能导致库存过剩、 缺货,以及资源的低效分配――特别是在旺季。由于更多的新技术和新系统已经被应用,比如:准时制造(just-in-time manufacturing) ,物流和库存管理在近几十年来有了显著改善。像UPS 这样的第三方物流供应商,也采用了高级算法来优化路线和包裹管理――这是我们看到未来 AI 能够发挥潜力的另一个领域。然而,目前的业务开展方式仍然存在一些挑战,特别是在诸如:时尚、服装和鞋等品类中,预测消费者想要什么,想要多少,愿意出多少钱尤为困难。
AI/ML 能帮助做什么?
推荐引擎。AI/ML 能够通过利用销售、消费者和内容组成的超大的数据集来提升推荐引擎的功能。早期的电子商务的一大机遇就是推荐引擎,当时主要是基于商品属性,而对用户喜好知之甚少。 像协同过滤这样的技术, 则可以充分利用已知客户喜好的相似性来为未知的偏好提供建议。
随着用户的快速增长和对计算资源的疯狂消耗,数据稀缺、用户/商品“冷启动”以及系统的扩展性成为亟待解决的问题。不过由于数据稀缺、用户/商品“冷启动” 、用户快速增加而导致的扩展性问题,对消费水平计算所需的资源开始变得不切实际。像 Zalando 和StitchFix 这样的公司已经致力于将销售数据、 商品属性与客户的偏好通过机器学习结合起来,Zalando 认为这种定制化的商品所带来的亲和力终将推动销售率的上涨。
客户支持。自然语言处理(NLP)和图像识别在零售业的客户支持方面和强化传统搜索参数方面也有各自的使用场景。就像最近收购了 Blackbird Technologies 的 Etsy 公司,利用了智能图像识别和自然语言处理技术提供了更加强大的搜索功能。 这显示出电子商务公司正在寻求方法来提高搜索结果的相关性来为他们的平台提供更大的优势。
自然语言处理为各公司提供了一个机会, 使其能发展自己的用户会话体验和商务。 最近收购 API.ai 的 Alphabet 和 Angel.ai 这样的公司正在创建一个以自然语言处理为支撑的人工智能系统,从而在信息和语音上对商务和客户提供支持。简而言之,像自然语言处理和图像识别等技术正在模拟人类的对产品属性的理解 (如: 视觉) , 而这是历史上从未出现过的。需求预测与价格优化。 AI/ML 技术能够通过客户所接触的数据和内容属性去预测用户对新商品新风格的需求。 对诸如服装这种流行趋势来也快去也快的行业, 预测消费者的需求对零售商来说是一个长期挑战。通过利用 AI/ML,零售商可以进行模式识别,更好的理解促, 销和价格弹性的本地影响,并将其纳入到营销和生产过程中。
,
像亚马逊这样的公司也正在朝这个方向前进,并在 2013 年末获得了一个叫做“预期包装运输”的专利。虽然在原始专利申请文中没有提到机器学习,但是这种类型的系统很明显的最终会通过深度学习进行协调。因为其不仅需要考虑季节性需求,还需要考虑天气、人口统计和独特的用户购物模式所带来的影响。
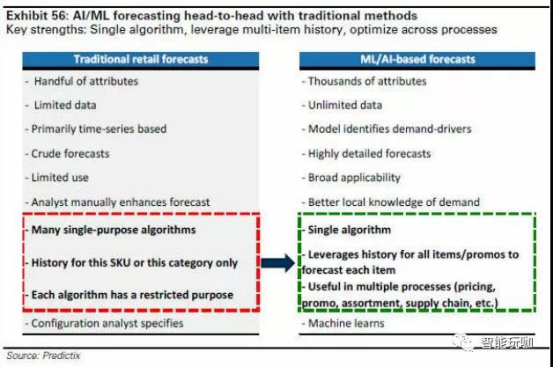
Dunnhumby(公司): 在定价、推广以及忠诚度方面的一体化 AI/ML 方案
Dunnhumby 是英国跨国零售商乐购(Tesco)的一家全资子公司,致力于同品牌和零售商一起优化零售体验。公司员工超过 2000 人,重点分析全球范围内的数据为库存管理、价格优化、促销和个性化提供见解。
过去,销售预测是一个基于历史数据做静态的基础分析以及对于分析结果的适当调整。而在今天,Dunnhumby 通过在整个价值链中整合了 AI/ML 在销售预测、库存管理和价格优化方面进行精确驱动。最终,更好的销量预测带来的多米诺效应贯穿了零售价值链,并且在库存和定价中增量分层的 AI/ML 驱动带来的效率,已经被证明对乐购(Tesco)等零售商降低成本和提高销售有重要意义。
销售预测。销售预测历来都是规则驱动的,对于 Dunnhumby 来说,机会存在于预测流程中建立机器学习技术来开发更准确、更有知识的模型。
360 度客户视图。优质的客户数据对于发展 360 度的客户视图是至关重要的。图片大约占所有新数据的 80%,因此,从图像中提取有用数据的能力是销售的关键。通过构建一个 360 度视图,零售商能够更有效率的在正确的渠道找到正确的客户。
消费和节省优化。许多零售商的主要促销工具是“消费和节省”建议。零售商通过调整折扣和消费的临界值看到了显著的性能改进。 应用机器学习技术来优化消费和节省临界值以及客户定位能够在促销计划中改善结果。
团队和技术的获得对于在零售中发展 AI/ML 是非常关键的。具体地说,在 2010 年获得KSS Retail,在 2013 年获得 Standard Analytics,在 2014 年获得一家合资企业和 Sandtable50%的股份,带来了数据科学、人工智能和解决方案,并被, 集成在 Dunnhumby 产品中。可解释性依然是机器学习解决方案的一个难点, 因为模型会随着数据分层的合并变得越来越不透明。所以,对于主要决策者来说通常会有成功率和模型的可解释性之间的取舍。如果可以通过一个更简单的模型提供相当比率的成功率提升,分析师倾向于给有可能接受可能更复杂的 AI/ML 的解决方案的客户提供这个更简单的解决方案。
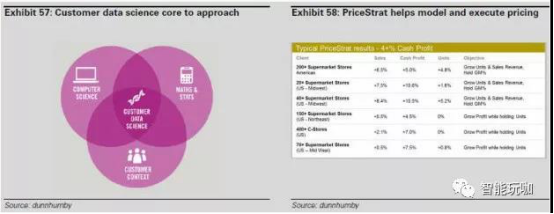
量化机会
降低成本提高需求预测。 目前根据美国劳动局统计美国的企业在劳动成本上每年花费近60 亿美元用于“分析过去的购买趋势、销售记录,商品的品质以及价格,以此来确定价值和收益。商品选择、顺序以及商品的支付授权” 。换句话说,批发和零售买家的任务是利用历史数据,专业经验,专业知识,来确定在未来两年内什么是购物者有兴趣购买。虽然电子商务的持续渗透增加了此任务的可用数据量,但是挑战仍然存在,将这些数据转化为理解的数据,不仅提高目标的定位,同时也向更有挑战性的运动趋势预测倾斜。我们相信这种类型的预测非常适合与 AL/ML 的分析能力相结合,不仅可以实现定量分析,也可以实现可视化的数据预测以及优化购买决策。我们估计全球 AL/ML 实践的整合,直到 2025 年在零售业方面每年大约可以节约 540 亿美元人工成本 。
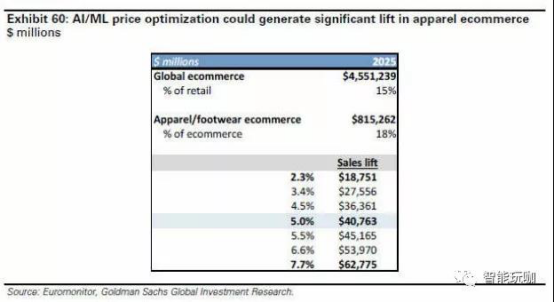
优化定价。为优化每日定价,HBS 和 Rue La La 联合进行的一项研究显示,机器学习过程的整合带来的平均收入增长约 9.7%(相关的 90%信任区间为[2.3%,17.8%]) 。鉴于了闪购模式和销售量的一些细微差别,我们将潜在改进从平均值提高 200bps 到 7.7%,并通过结合 AI / ML 来考虑基于预测需求优化定价的多变问题,可以实现 2.3%-7.7%的改进。零售业, 特别是服装和鞋类中的动态定价的一个挑战是缺乏新时尚风格, 颜色搭配等等的用于预测需求的历史数据。 应用机学习能够同时分析数百个产品和属性, 将最终实现从更广泛的数据集比传统预测更好地评估和优先化洞察。因此我们看到使用 AI / ML 所带来的定价优化将会使 2025 年全球服装和鞋类电子商务的年销售额平均增长 410 亿美元。
谁可能被扰乱?
随着 AI / ML 在零售价值链中各种流程的整合,证明其在库存管理、生产和定位方面的高效对一些公司和员工都具有破坏性。 我们认为, 过度构建的大型零售商可能受到更多影响,因为以 AI / ML 驱动的高效价值链可以帮助小零售商赶在更大竞争对手之前进一步完善他们的需求预测和库存管理。
同时,对于更加严格的库存管理方式,那些之前从大型零售商和品牌商过度购买和/或过剩生产,并从中获益的折扣零售商,也受到了严重的冲击。随着更加准确的生产和需求预测,折扣零售商从生产超支、订单取消和预测错误判断中,获益的机会也大大减少。回顾,截至 2015 年春的零售年度(IHL),因库存过剩导致销售额损失超过 470 亿美元。
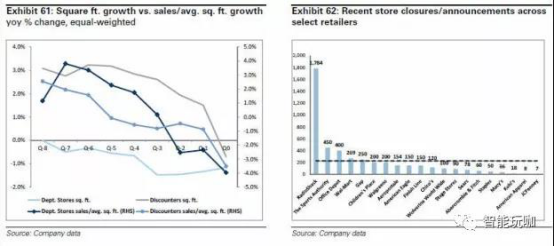
能源
预计 2025 年,将累计节省成本 140 亿美元石油和天然气是典型的资本密集型行业, 常常存在极端条件下的操作。设备的可靠性极端重要,设备故障和过程纰漏对项目收益影响巨大。为避免此种情况,生产企业通常会对设备数量和工程师做多层后手准备。人工智能/机器学习在一定程度上可以提高设备的可靠性,从而降低企业的资本支出和运营支出。收益是巨大的, 我们估计石油和天然气行业的资本支出,运营支出和库存管理减少1%,可以在 10 年内节省大约 1400 亿美元。在能源行业,我们认为一家公司特别适合采用人工智能/机器学习来降低自身的运营成本和客服成本 - 斯伦贝谢(SLB)。
机遇是什么?
在石油和天然气行业,AI/ML 的价值主要体现在以下几个方面:
工程规划。世界各地的大型能源项目可能花费数百亿美元,可能有 3 至 5 年的交付周期。管理层根据一系列宏观假设批准这些项目,例如石油价格及其主要产品/服务的供需情况。AI/ML 应用程序可以更好地评估项目的可行性,公司可以做出更好的决策,减少低产出的项目。此外。通过结合行业/公司在这些项目中的过去经验,并根据项目计划成本制定执行计划,人工智能/机器学习应用程序可以帮助更准确地确定项目成本。
提高设备可靠性。计划外设备停机和非生产性时间消耗是项目成本升级的主要驱动因素。石油服务业高度重视提高设备可靠性,人工智能/机器学习在这方面可以提供有效帮助。该行业尤其针对海底 BOP(防喷器)--通常是钻机上最易发生故障的物品,每个故障都可能使深水作业花费至少约$ 1000 万 - $ 1500 万(见下面的案例研究) 。类似地,为了****限度地减少压力泵故障导致的时间消耗, 服务公司带来的泵数量是无故障情况的两倍。 提高设备可靠性不仅降低设备维护成本,而且降低项目的部署成本。
提高碳氢化合物资源的识别, 定位和开采。 查找石油和天然气储量及其开采产生大量数据,当进行地质地震分析以确定油气储量的位置时。 类似的, 在钻井和对井进行测试是也会产生大量数据,最终,当进行生产时也会产生大量数据。将地质数据,生产相关数据和硬件数据结合, 有利于达到****开采产出, 并且来自一个项目的研究成果可以应用于更经济的未来项目设计。
增加下游行业的正常运行时间。计划和计划外停机的严重程度也影响了下游行业的盈利。在天然气管道中, 压缩机的正常运行时间对于保持良好的流量很重要, 而管道的**** “检查”可以减少意外停机和泄漏。 类似地, 炼油和石油化工行业的计划内和计划外停机具有很高的机会成本。即使使用率提高 1%,对节省成本也是意义重大的。
痛点是什么?
能源行业在不同业务层面高度分散。在美国,近乎 400 个勘探&生产涉及泥板岩资源的开采,并且许多上游公司分布在世界各地。在石油服务产业里,三个巨头公司(斯伦贝榭公司,哈里伯顿公司,贝克休斯公司) 主导着大多数技术驱动型企业,但是还有很多提供专业商品化服务的供应商, 例如: 钻机和压力泵。 处于中游的提炼和石油化学业务也同样被分散。关键数据分散在众多参与者的现状带来了挑战。结果就是一个公司不能同时掌握地质、设备和作业流程的数据。 并且, 即使某些公司可能没有财政实力或者技术实力去运用一些掌握关键数据,但是这些公司可能不愿意分享它。
数据访问。此外,产业数据跨越了地理范围,因为油和天然气存储分布在世界各地,通常, 这些数据在国家石油公司手中, 这意味着对数据的访问可能受到监管挑战的限制。 此外,数据跨越各种各样的时间范围,像最早的油井是 1880 年开采。
最后, 横跨整个价值链的数据分析是最有用的。 但是一般的能源公司主要涉及这个产业的一个方面,不能访问价值链的所有部分,这种情况限制了数据分析达到最优效果。数据可用性。 另外一个痛点是关键数据的可用性, 在过去企业可能没有在烃链的关键部分放置传感器,这些关键部分能帮助人工智能/机器学习应用。举一个例子,企业可能有防喷器出现故障的频繁次数和在操作周期内防喷器遇到了什么压力的关键数据, 但是没有防喷器中的各种各样的线圈或者电子部件的温度,电流,电压数据。企业现在在新的产品中放这些传感器,公司需要一段时间获得这些数据。
开展业务的当前方法是什么?
企业仍然使用传统的方法开采石油和天然气存储, 使用的技术有了更新但是没有真正的革新。 使企业难以变化的关键问题是企业正在使用各种各样的开采井, 限制了在业务的各个部分上整合性和内聚性。举一个例子,石油和天然气存储的拥有者设计了整个项目,然后把工作分给不相关的服务提供者。勘探&生产有最多的信息,但是他们没有完全懂得服务公司能提供什么, 并且经常保持与服务公司一定距离, 相信过分的依靠他们导致未来的费用增加和 IP 泄露。为了能源产业能从人工智能/机器学习中有所获得,勘探&生产和服务部门需要更好的共享数据,并且一个更合作的模型需要出现。在近海区域,随着国际石油公司要降低成本,他们在与一些像斯伦贝榭(SLB) 或者 FMC 科技这种样整合很好的服务公司合作中处于领导地位。
AI/ML 能帮助做什么?
AI/ML 的作用,可以从如下几个方面进行介绍:
通过纳入从历史信息中获得的知识提高产品的可靠性,AI/ML 还可以帮助缩短产品开发、现场试验和商业化之间的时间。通过减少钻井的时间和成本,更好地定位油气储量,从而降低油田开发成本。通过提高设备正常运行时间和降低维护成本,降低现场寿命周期服务的生产成本。提高了海上和陆地钻机的正常运行时间,而提高了钻井效率,减少了钻井所需的天数。基于 AI/ML 的数据分析,可以降低下游产业的停机维护时间。
量化机遇
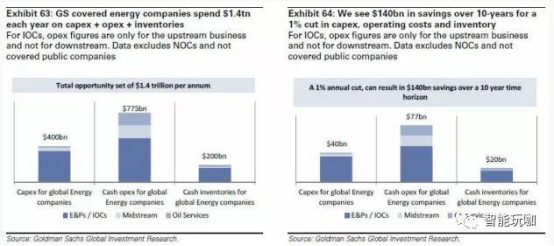
2016 年,我们预计高盛集团(GS)投资亚洲新兴工业化国家和地区的石油和天然气公司将花费近 4000 亿美元的资本支出。 在此外, 石油和天然气行业应该再花费 7750 亿美元的运营成本(不包括为炼油和石油化工的折旧、折耗及摊销出售的商品成本) ,并拥有 2000 亿美元的库存。
我们预估,如果基于 AI/ML 的应用程序,每降低 1%的资本支出和运营支出,并且行业通过更好的库存管理将库存减少1%,那么10年内该行业的总节约量将达到 1400 亿美元。
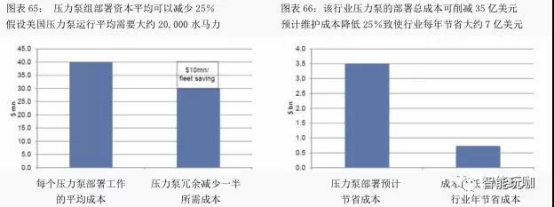
降低压力泵队的成本。 行业里的压力泵队拥有非常高的设备磨损和维护,通常占收入成本的 10%-15%。在过去五年中,压力泵是一个平均年收入达到 300 亿美元的业务,该行业每年花费近 36 亿美元维持压力泵设备,这个数字不包括设备升级等主要资本的成本。在过去的 5 年中,压力泵行业平均年收入 300 亿美元,每年花费近 36 亿美元进行设备保养,这个数字还不包括设备升级等主要资本成本。
斯伦贝谢是美国第二大压力泵制造商, 最近开始了一项计划, 集中管理其压力泵组的部署和运行。该公司在压力泵上安装先进的传感器,传感器收集数据,并传回其位于休斯顿的力泵失效之前将其从操作中移除。进而大大降低维护成本,以及现场所需备用设备数量。斯伦贝谢估计,这一应用可在 6 个月内为其单个压力泵组节省 400 万美元。
美国压力泵运行平均需要大约 20,000 水马力。 然而,该行业通常需要大约 40,000 水马力,以便在设备故障情况下保持冗余、降低非生产性工作时间。这种冗余水平对于石油和天然气工业是低效的。 如果通过像斯伦贝谢这样的举措提高设备可靠性, 井场所需设备冗余水平将会降低。 预计现场所需冗余减少一半, 压力泵的部署成本可以减少 25%, 从大约 4000万美元降低到 3000 万美元。类似地,预测分析可以减少设备维护成本,以 1400 万水马力、85%设备利用率为标准,预计维护成本降低 25%致使行业每年节省大约 7 亿美元(即10年70亿美元)。
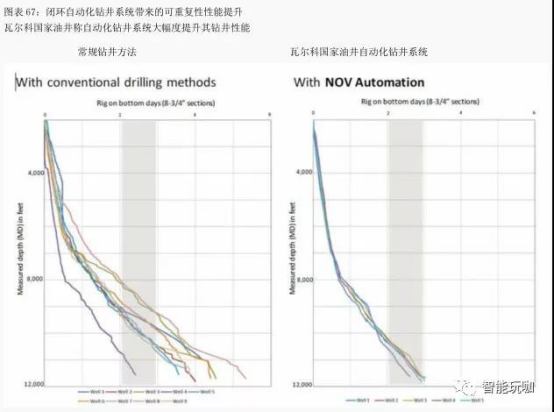
通过“未来钻机”改善钻井时间。石油和天然气工业钻探深水井时,每日需要花费 70万至 100 万美元,而水平页岩井的钻井成本约为每天 6 万美元。因此,行业可以从其钻井计划中节约可观的成本。
可以通过三种方式减少钻井时间:改善设备正常运行时间,特别是在诸如防喷器(尤其是海底)和顶部驱动器等问题项目上。了解井中可能遇到的情况,选择正确的井底组件。
通过在地面设备和“井底钻具组件”之间建立“闭环信息系统”,优化钻井性能。提高系统自动化程度,减少“机组质量”对可重复性性能的影响。该行业正在积极通过筛选数据、 寻找能够消除即将到来问题的前沿信号, 来减少防喷器和顶级驱动器的停机时间。
类似地, 先前钻井数据的分析可以帮助石油公司为特定井设计****钻井液和钻头。此外,通过在钻头附近的传感器与钻机面板之间建立闭环系统, 可以设计 “智能钻机”,“智能钻机”根据井下条件,自动调节****“钻压”和施加在钻机上的扭矩。人工智能和机器学习可以有助于持续改进,提高可重复性性能。
钻井中的关键问题之一是 “人为干预” 的影响, 并且业界已经发现, 即使在类似的井中,钻井性能也可以根据团队操作质量而显着变化。自动化可以减少“人为干预”对钻井性能的影响。
瓦尔科国家油井、 斯伦贝谢和纳伯斯工业工业正在研究新一代钻井概念。下面的图表显示,瓦尔科国家油井的自动化系统可以将井底钻井时间平均减 30%。更重要的是,瓦尔科国家油井的自动化系统将钻井时间缩短到2.5至3.0天,而传统钻井方法则为2.5至5.5天。斯伦贝谢还在建设“未来钻机”,并期望今年年底前产出第一个原型。
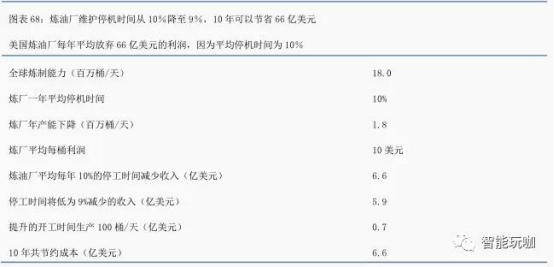
提高炼油厂正常运行时间。美国炼油工业的生产基数约为 1800 万桶/日,平均利用率约为 90%, 该行业计划内和计划外维护时间占 10%。 平均而言, 炼油利润约为每桶 10 美元,这意味着该行业要为每桶未生产的炼油放弃 10 美元利润。预计通过更好的数据分析,该行业可以将保养等相关停机时间从 10%减少到 9%,炼油厂将实现每年 6.57 亿美元的额外利润,十年约 66 亿美元。
谁会被影响?
小型或者不太先进的能源公司,以及资本有限且技术专长型公司将受到****负面影响,因为具备良好定位的公司采用人工智能和机器学习技术降低成本。 这对于勘探生产和石油服务业同样如此。 主要获胜者将是那些有远见的公司, 他们过去在获取和存储数据方面投入了资金。有些公司不仅具有研究 AI/ML 等新技术的财务能力,而且乐于研究乐于创新,此类公司同样可以取得成功。
通过整合具备关键数据库和具备技术实力的公司, 石油和天然气工业可以得到进一步巩固。2016 年 11 月 1 日,GE 油气公司和 Baker Hughes 宣布签署协议,创建全新的全数字化工业服务公司。GE 首席执行官 Jeff Immelt 说: “这一交易加速我们将数字框架延伸到石油和天然气行业的进程。 油田服务平台对于向客户提供数字化服务至关重要。 我们预计 Predix将成为行业标准,同时也是将成为改善客户体验的代名词。
在我们看来,在今年早些时候收购 CAM 的 SLB,将是采用人工智能和机器学习技术的一个大赢家,我们相信它已经获得最广泛的数据。虽然访问数据是一个关键区别,但斯伦贝谢通过将技术和文化融入其中来对其进行了进一步区分。 该公司设立两个团队, 一个在帕洛阿尔托,一个在剑桥负责大数据和机器学习分析。该公司一直致力于油田领域数字化,这在未来会被证明是非常有用的。
我们看到许多小型压力泵从长远上看存在问题,虽然一些近期周期性上升是可能的。此外,随着斯伦贝谢推出“未来之钻”,美国陆上钻探的形势也将随之改变。
人工智能创新:GOOGL(谷歌), AMZN(亚马逊)
GOOGLE(谷歌)在人工智能领域正在做什么?
在过去二十年中,Google 的搜索算法已经快速发展。从 1998 年的 PageRank 到 2015 年的 RankBrain,该公司已经从基于链接的网站排名转变为采用 AI 驱动的查询匹配系统,后者能够不断适应那些独特的搜索(占谷歌所有搜索的 15%)。在云技术方面,公司五月份公布了针对平台的定制化硬件加速器方面取得的进展,一种定制化的 ASIC,亦即 TPU,这一进展对 2015 年开源的机器学习软件库 TensorFlow 进行了补充。 过去三年中, 在与人工智能相关的收购战中,公司也当仁不让。被收购的公司中,最知名的当属 DeepMind,它提升了 Alphabet 的神经网络功能并已经将其应用于各种人工智能驱动的项目中。
为什么会做这样的事情呢?
Google 是在搜索领域中使用算法的先驱。该公司继续将自然语言处理应用到匹配人们的搜索意图,以达到期望的目标,这也不断加强了公司在该领域的竞争优势。使用TensorFlow, 该公司的开源应用程序为其他基于云的平台创建了先例, 并允许研究团体利用公司的资源来推进 AI 的集成。
AMZN(亚马逊)在人工智能领域正在做什么?
亚马逊正在公司内部和云端使用机器学习技术。2015 年 4 月,公司发布 Amazon ML,这款机器学习服务能够为对云数据的使用提供机器学习功能(无需之前的客户经验)。公司紧随谷歌的开源步伐,今年 5 月开源了 DSSTNE,一个针对推荐深度学习模型的的库。通过改善搜索、定制化产品推荐以及语音识别、增加有质量的产品评价,公司内部也在使用机器学习改善端到端的用户体验。
为什么会做这样的事情呢?
借助 AWS,亚马逊成为全球****的云服务商,可能也是最成熟的人工智能平台。借助Amazon ML,公司成为作为服务的人工智能(AI-as-a-service)生态系统的领先者,将复杂的推理能力带到之前几乎没有机器学习经验的公司办公室当中。无需基于定制的复杂应用,AWS 用户就能使用机器学习训练模型,评估以及优化潜力。
亚马逊推荐引擎使用了机器学习,在匹配用户意图以及可欲结果方面,具有竞争优势,也为公司创造了商机。 公司正更加高效地利用收集到的数据合理化用户购物体验, 也让电子商务体验更具互动性。随着 DSSTNE 的开源,亚马逊也与其他科技巨头一起,推动科技社区的人工智能进步。
人工智能创新:AAPL(苹果), MSFT(微软)
Apple (AAPL)在人工智能领域正在做什么?
苹果已经是过去一年左右中最活跃的 AI 收购商之一,收购的公司如 Vocal IQ,Perceptio, Emotient, Turi, 以及 Tuplejump。几乎同时收购了 Vocal IQ 和 Perceptio,公司请来了 Johnathan Cohen,当时还是英伟达 CUDA 库以及 GPU 加速软件项目的负责人。近期,据报道,公司请来 Ruslan Salakhutdinov 担任人工智能研究总监,这也标志着公司人工智能战略的转型。在此之前,公司最初人工智能成果之一是 Siri , 第一款嵌入移动技术的虚拟助手,2014 年,其语音识别技术被移入神经网络系统。
为什么会做这样的事情呢?
直到去年,苹果已经取得相对专有的机器学习成就; 2015年10月,Bloomberg Businessweek 报道, 在大众消费方面, 苹果研究人员还没发过一篇与人工智能有关的论文。这一策略转型多少与新的、与人工智能相关的雇佣与收购有关,科技记者 Steven Levy 在 Backchannel 的一篇报道强调公司已经在人工智能领域活跃一段时间了。
特别是,公司收购 Turi 突出了公司要按规模推进非结构数据和推论, 以及开放给更为广泛的人工智能研究社区。这次收购,配以基于收购公司技术的较小应用,反映出苹果致力于用这些新技术创新公司产品。
Microsoft (MSFT)在人工智能领域正在做什么?
根据 CEO Satya Nadella 的说法,微软正在大众化人工智能(democratizing AI)。公司的人工智能和研究团队(总人数大约 5 千多) ,关注改变人类体验和与机器的互动。微软已经积极地将新的、融合人工智能的功能嵌入公司核心服务中,并在对话计算(比如Cortana) 、 自然语言处理 (SwfitKey) 等方面取得进展。 公司正进一步打造基于 GPU 和 FPGA 的云(Azure) ,在公司所谓的更高水平的人工智能服务,比如语音识别、图片识别以及自然语言处理当中,为机器学习提供动力和速度。
为什么会做这样的事情呢?
两个单词:人工智能大众化(democratizing AI)。由于这个行业中的公司将研究计划甚至库开放给人工智能研究社区, 微软发明了这一表述, 用来解释许多领先的人工智能创新者的举动。去年,微软在人工智能领域颇为活跃,正式发布了产品以及研究计划,并宣布了一个新的人工智能和研究小组(2016 年 9 月下旬)。
微软的 FPGA 表现突出了人工智能可以为普通商业或个人带来什么;不到十分之一秒,它就翻译完了整个维基百科 (30 亿个单词和 500 万条条款)。 而且伴随着虚拟助理 Cortana, Siri, Alexa 以及其他助理之间的竞争,进一步将人工智能研发融入广泛使用的产品中去,通过产品进步吸引客户似乎是必须的。
人工智能创新:FB(Facebook), CRM
Facebook (FB)在人工智能领域正在做什么?
Facebook 人工智能研究部门(FAIR,2013 年)的策略是在更广泛的研究社区背景下研发技术。这个团队以推进无监督表征学习(比如,观察世界、而不是借助人类算法干预,借助对抗网络进行学习) 的进步而为众人所知。 应用机器学习部门 (AML) 在 FAIR 之后成立,聚焦将研究应用到公司产品中,时间限制为月或季度(而不是年) 。公司正将机器学习功能应用到各种垂直领域中,比如面部识别,机器翻译以及深度文本(DeepText)语言或文本学习。
为什么会做这样的事情呢?
公司已经发布了多个无监督学习方面的研究成果,随着机器学习超越从「正确答案」中学习,开始聚焦独立的模式识别,无监督学习已经成为一个重要的焦点领域。无监督学习有望去除更多的、与大数据有关的人类成分,公司在 Yann Lecun 的带领下,正引领该领域的研究。
今年五月,公司发布的 FBLearner FLow 合理化了端到端 UI(从研究到工作流程、实验管理以及视觉化和比较输出) 。 公司的人工智能项目和工作流程应用不限于 AML 成员, 公司各部门领域都可以使用借鉴。 这样一来, 公司就可以利用研究部门之外所取得的人工智能进步。
Salesforce.com (CRM)在人工智能领域正在做什么?
在 2014 年和 2015 年,Salesforce 开始解释自己的 Apex 开发平台如何可被用在Salesforce1 云上完成机器学习任务。从此,该公司开始在人工智能上投入更多的资源,收购了多家人工智能公司, 包括 Minhash、PredictionIO 和MetaMind。在9月份, Salesforce 推出了 Einstein――一个面向多平台的基于人工智能的云计划。该计划专注于将人工智能融入销售云、市场云、服务云、社区云、IoT 云和app云。
为什么会做这样的事情呢?
Salesforce Einstein 有潜力促进商业使用数据的方式。在销售云中,该公司希望让各个组织通过预测销售线索得分、洞见机会以及自动捕捉活动来优化销售机遇。市场和服务云将提供预测参与度得分,来分析消费者使用情况。还能提供预测客户,从而帮助定位市场,并基于趋势和用户历史通过自动案例分类更快解决消费者服务事件。Salesforce 用微妙的使用案例将机器学习带到云中,强调它对公司核心竞争力的影响。人工智能创新:NVDA(英伟达), INTC(英特尔)
NVIDA(英伟达)在人工智能领域正在做什么?
英伟达已经从之前电子游戏 GPU 生产商转型为机器学习应用硬件厂商。2015 年年底,公司表示,较之使用传统CPU,使用了 GPU 神经网络的训练速度提升了 10到20倍。尽管英特尔重金投入的 FPGA(作为 GPU 的替代产品)加入硬件市场角逐,但是,GPU 的机器学习应用能实现更加密集的训练。相对而言,FPGA 可以提供更快、计算密集程度更低的推理和任务;这说明市场会根据实际应用案例区分对待。过去五年,到 2016 年 6 月为止,英伟达所占 GPU 市场份额已经从二分之一上升到近四分之三。
为什么会做这样的事情呢?
在人工智能创新公司和学术机构中, GPU 加速的深度学习一直是许多项目的前沿。英伟达所占据的市场份额意味着, 随着人工智能越来越成为未来几年中大型商务的中心议题, 公司可以从中获益。
使用公司产品的一个例子,俄罗斯的 NTechLab,使用 GPU 加速的深度学习框架来训练面部识别模型,识别密集集会中的个人,并在 AWS 中利用这些 GPU 进行推理。作为一种选择, 许多大学也使用英伟达的 Tesla 加速器来模拟可能的抗体突变, 这种变异可能会击败进化中的伊波拉病毒,将来研究会进一步关注流感病毒。
Intel (英特尔)在人工智能领域正在做什么?
英特尔的战略比较独特, 其使用的案例多种多样。 2016 年年中, 公司发布了第二代 Xeon Phi 产品系列,以其高性能计算(HPC)能力著称,它可以让人工智能扩展到更加大型的服务器网络和云端。在硬件不断进步的同时,公司也下重金投资 FPGA,这主要归功于其推理速度和灵活的可编程性。英特尔令人瞩目的收购包括 Nervana(深度学习) ,以及 Altera――该公司将 FPGA 的创新带入了英特尔。
为什么会做这样的事情呢?
英特尔关注 FPGA 创新补足了英伟达对GPU的关注。当处理大型数据库(微软等许多大公司用来测试大数据分析的边界),FPGA 能够提供更加快速的推理速度。在物联网的应用环境中,公司也宣布了一个计划, 旨在将学习技术融入可穿戴微芯片中(显然是通过 Xeon Quark)。物联网和人工智能的衔接有助于为公司和个人日常使用案例的数据搜集机制提供机器学习解决方案。
人工智能创新:Uber,IBM
Uber 在人工智能领域正在做什么?
Uber 正在使用机器学习优化 UberX ETA 以及接送地点的准确性。为了实现这一点,需要数百万之前搭乘记录的数据点来探测常规交通模式,从而可以相应调整 ETA/接送地点。今年 9 月,Uber 展开了一个自动驾驶试点项目,地点位于匹兹堡,由来自 CMU 的研究人员(受雇于 Uber)负责该项目,很多大型汽车制造商业参与了进来。该公司还和沃尔沃达成了一项合作(金额300万美元),研发协作也为这个试点项目提供了机遇。不过,公司并不止步于小轿车。公司收购了一家自动卡车创业公司 Otto,今年十月在科罗拉多,公司试点快递了5 万瓶啤酒。
为什么会做这样的事情呢?
Uber 的机器学习负责人 Danny Lange 在接受 GeekWire 的采访中提及,他们的团队正在将这种技术无缝供给公司的其他团队, 这些团队无需具备机器学习背景就可以使用 APIs。这也能让公司不同部门能高效利用机器学习基础架构, 例如, UberX、 UberPool、 UberEats 以及自动驾驶工具都使用到了公司的人工智能技术。
IBM 在人工智能领域正在做什么?
IBM 在全球有 3000 多名研究人员。 过去十年, IBM 在认知计算上超过有 1400 项专利,下一代云上有 1200 项,在硅/纳米科学上有 7200 项专利。IBM Watson 利用自然语言处理机器学习技术识别模式, 并提供在非结构数据上的洞见, 据该公司表示这代表如今所有数据的 80%。其他 Watson 产品包括 Virtual Agent,一个响应分析的自动消费者服务体验;Explorer,这是一个分析并连接大量不同数据集的工具。
为什么会做这样的事情呢?
IBM 一直是该领域的先驱,有着极大的成就,包括上世纪90年代的DeepBlue和2011年的 Watson。Watson 的应用包括医疗中的病人治疗分析, 基于 twitter 数据的股票推荐,零售中消费者的行为分析,以及对抗网络安全威胁。据财富报道,GM 将 Watson 加入到了汽车中,在 OnStar 系统上结合了 Watson 的能力。
人工智能创新:百度
百度在人工智能领域正在做什么?
在 2016 年 9 月 1 日推出了百度的 AI 研究,百度大脑,它由三个元素组成:1)、AI 算法模拟人类神经网络,用数百数十亿样品的大量的训练。2)对数十万服务器和许多 GPU 集群进行操作的计算能力(图形处理单元)用于高性能计算(HPC); HPC 允许更多可扩展的深度学习算法。 百度是第一个宣布这个架构的组织,正在与 UCLA 合作。3)标签数据,百度已经收集了数万亿页的网页, 包括几百亿个视频/音频/图像内容, 数十亿次的搜索查询以及数百亿次的位置查询。训练特定型号的机器要求非常高的计算能力和 4T 数据。
为什么会做这样的事情呢?
人工智能正在改进百度全线产品的用户体验和提升用户粘性, 也在推动针对每一用户的定制化高质量内容。 建立一个内部平台来运行从网页搜索到广告投放的带有标签数据的深度学习实验,能够预测点击率(CTR) ,这会直接影响百度的广告投放,因此也是它们目前的主要收益。此外,基于人工智能的技术也能带来更高的 CTR,而且每点击成本的降低也能促进变现。
Copyright © 版权所有:江苏嘉图工程科技有限公司 苏ICP备16005482号-1
本站部分内容来源自网络,如果侵害了您的合法权益,请您及时与我们联系,我们会在第一时间删除相关内容!